
The structure of the pattern database
The pattern database is organized as follows:
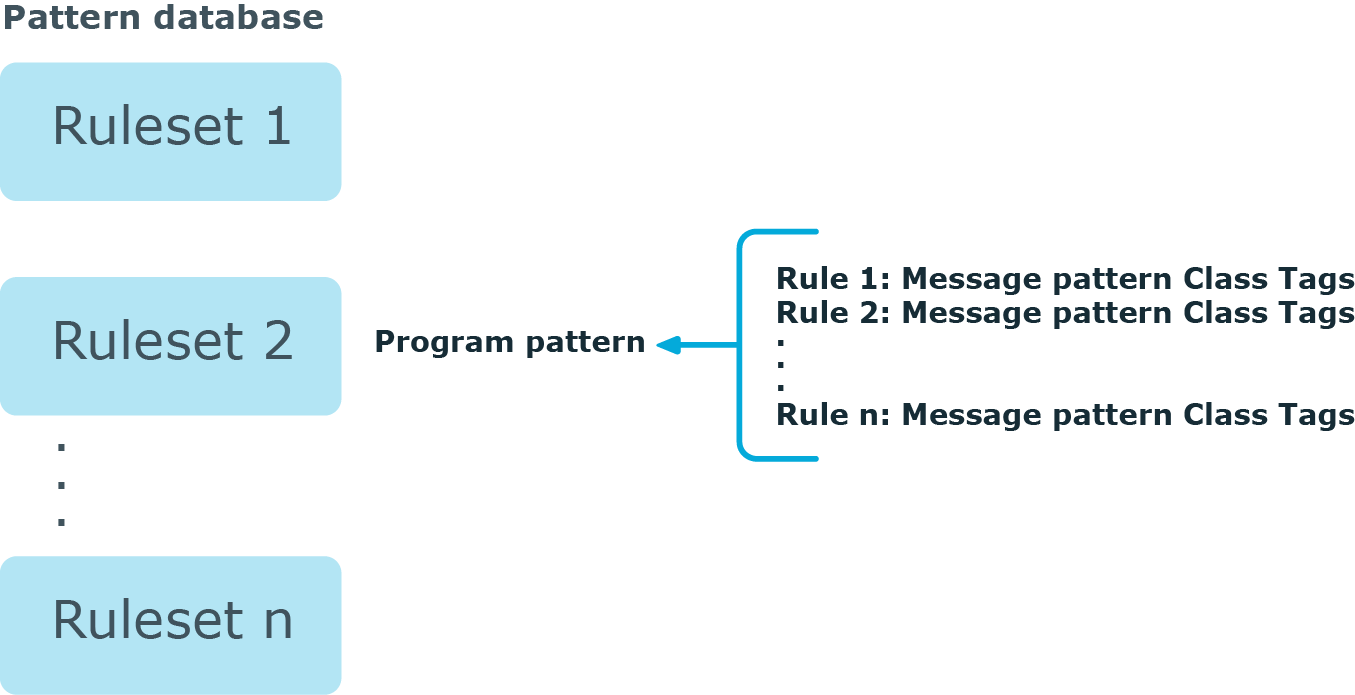
Figure 19: The structure of the pattern database
-
The pattern database consists of rulesets. A ruleset consists of a Program Pattern and a set of rules: the rules of a ruleset are applied to log messages if the name of the application that sent the message matches the Program Pattern of the ruleset. The name of the application (the content of the ${PROGRAM} macro) is compared to the Program Patterns of the available rulesets, and then the rules of the matching rulesets are applied to the message. (If the content of the ${PROGRAM} macro is not the proper name of the application, you can use the program-template() option to specify it.)
-
The Program Pattern can be a string that specifies the name of the application or the beginning of its name (for example, to match for sendmail, the program pattern can be sendmail, or just send), and the Program Pattern can contain pattern parsers. Note that pattern parsers are completely independent from the syslog-ng parsers used to segment messages. Additionally, every rule has a unique identifier: if a message matches a rule, the identifier of the rule is stored together with the message.
-
Rules consist of a message pattern and a class. The Message Pattern is similar to the Program Pattern, but is applied to the message part of the log message (the content of the ${MESSAGE} macro). If a message pattern matches the message, the class of the rule is assigned to the message (for example, Security, Violation, and so on).
-
Rules can also contain additional information about the matching messages, such as the description of the rule, an URL, name-value pairs, or free-form tags.
-
Patterns can consist of literals (keywords, or rather, keycharacters) and pattern parsers.
NOTE: If the ${PROGRAM} part of a message is empty, rules with an empty Program Pattern are used to classify the message.
If the same Program Pattern is used in multiple rulesets, the rules of these rulesets are merged, and every rule is used to classify the message. Note that message patterns must be unique within the merged rulesets, but the currently only one ruleset is checked for uniqueness.
If the content of the ${PROGRAM} macro is not the proper name of the application, you can use the program-template() option to specify it.
How pattern matching works
Figure 20: Applying patterns

The followings describe how patterns work. This information applies to program patterns and message patterns alike, even though message patterns are used to illustrate the procedure.
Patterns can consist of literals (keywords, or rather, keycharacters) and pattern parsers. Pattern parsers attempt to parse a sequence of characters according to certain rules.
NOTE: Wildcards and regular expressions cannot be used in patterns. The @ character must be escaped, that is, to match for this character, you have to write @@ in your pattern. This is required because pattern parsers of syslog-ng are enclosed between @ characters.
When a new message arrives, syslog-ng attempts to classify it using the pattern database. The available patterns are organized alphabetically into a tree, and syslog-ng inspects the message character-by-character, starting from the beginning. This approach ensures that only a small subset of the rules must be evaluated at any given step, resulting in high processing speed. Note that the speed of classifying messages is practically independent from the total number of rules.
For example, if the message begins with the Apple string, only patterns beginning with the character A are considered. In the next step, syslog-ng selects the patterns that start with Ap, and so on, until there is no more specific pattern left. The syslog-ng application has a strong preference for rules that match the input string completely.
Note that literal matches take precedence over pattern parser matches: if at a step there is a pattern that matches the next character with a literal, and another pattern that would match it with a parser, the pattern with the literal match is selected. Using the previous example, if at the third step there is the literal pattern Apport and a pattern parser Ap@STRING@, the Apport pattern is matched. If the literal does not match the incoming string (for example, Apple), syslog-ng attempts to match the pattern with the parser. However, if there are two or more parsers on the same level, only the first one will be applied, even if it does not perfectly match the message.
If there are two parsers at the same level (for example, Ap@STRING@ and Ap@QSTRING@), it is random which pattern is applied (technically, the one that is loaded first). However, if the selected parser cannot parse at least one character of the message, the other parser is used. But having two different parsers at the same level is extremely rare, so the impact of this limitation is much less than it appears.
Artificial ignorance
Artificial ignorance is a method used to detect anomalies. When applied to log analysis, it means that you ignore the regular, common log messages — these are the result of the regular behavior of your system, and therefore are not too concerning. However, new messages that have not appeared in the logs before can signal important events, and should be therefore investigated. "By definition, something we have never seen before is anomalous" (Marcus J. Ranum).
The syslog-ng application can classify messages using a pattern database: messages that do not match any pattern are classified as unknown. This provides a way to use artificial ignorance to review your log messages. You can periodically review the unknown messages — syslog-ng can send them to a separate destination, and add patterns for them to the pattern database. By reviewing and manually classifying the unknown messages, you can iteratively classify more and more messages, until only the really anomalous messages show up as unknown.
Obviously, for this to work, a large number of message patterns are required. The radix-tree matching method used for message classification is very effective, can be performed very fast, and scales very well. Basically the time required to perform a pattern matching is independent from the number of patterns in the database. For sample pattern databases, see Downloading sample pattern databases.
Using pattern databases
To classify messages using a pattern database, include a db-parser() statement in your syslog-ng configuration file using the following syntax:
Declaration:
parser <identifier> {
db-parser(file("<database_filename>"));
};Note that using the parser in a log statement only performs the classification, but does not automatically do anything with the results of the classification.
Example: Defining pattern databases
The following statement uses the database located at /opt/syslog-ng/var/db/patterndb.xml.
parser pattern_db {
db-parser(
file("/opt/syslog-ng/var/db/patterndb.xml")
);
};
To apply the patterns on the incoming messages, include the parser in a log statement:
log {
source(s_all);
parser(pattern_db);
destination( di_messages_class);
};
By default, syslog-ng tries to apply the patterns to the body of the incoming messages, that is, to the value of the $MESSAGE macro. If you want to apply patterns to a specific field, or to an expression created from the log message (for example, using template functions or other parsers), use the message-template() option. For example:
parser pattern_db {
db-parser(
file("/opt/syslog-ng/var/db/patterndb.xml")
message-template("${MY-CUSTOM-FIELD-TO-PROCESS}")
);
};
By default, syslog-ng uses the name of the application (content of the ${PROGRAM} macro) to select which rules to apply to the message. If the content of the ${PROGRAM} macro is not the proper name of the application, you can use the program-template() option to specify it. For example:
parser pattern_db {
db-parser(
file("/opt/syslog-ng/var/db/patterndb.xml")
program-template("${MY-CUSTOM-FIELD-TO-SELECT-RULES}")
);
};
Note that the program-template() option is available in syslog-ng OSE version
NOTE: The default location of the pattern database file is /opt/syslog-ng/var/run/patterndb.xml. The file option of the db-parser() statement can be used to specify a different file, thus different db-parser statements can use different pattern databases.
Example: Using classification results
The following destination separates the log messages into different files based on the class assigned to the pattern that matches the message (for example, Violation and Security type messages are stored in a separate file), and also adds the ID of the matching rule to the message:
destination di_messages_class {
file(
"/var/log/messages-${.classifier.class}"
template("${.classifier.rule_id};${S_UNIXTIME};${SOURCEIP};${HOST};${PROGRAM};${PID};${MESSAGE}\n")
template-escape(no)
);
};
Note that if you chain pattern databases, that is, use multiple databases in the same log path, the class assigned to the message (the value of ${.classifier.class}) will be the one assigned by the last pattern database. As a result, a message might be classified as unknown even if a previous parser successfully classified it. For example, consider the following configuration:
log {
...
parser(db_parser1);
parser(db_parser2);
...
};
Even if db_parser1 matches the message, db_parser2 might set ${.classifier.class} to unknown. To avoid this problem, you can use an 'if' statement to apply the second parser only if the first parser could not classify the message:
log {
...
parser{ db-parser(file("db_parser1.xml")); };
if (match("^unknown$" value(".classifier.class"))) {
parser { db-parser(file("db_parser2.xml")); };
};
...
};For details on how to create your own pattern databases see The syslog-ng pattern database format.
Drop unmatched messages
If you want to automatically drop unmatched messages (that is, discard every message that does not match a pattern in the pattern database), use the drop-unmatched() option in the definition of the pattern database:
parser pattern_db {
db-parser(
file("/opt/syslog-ng/var/db/patterndb.xml")
drop-unmatched(yes)
);
};
Note that the drop-unmatched() option is available in syslog-ng OSE version