Starting with version
Preface
Introduction to syslog-ng
What syslog-ng is
What syslog-ng is not
Why is syslog-ng needed?
What is new in syslog-ng Premium Edition 7?
Who uses syslog-ng?
Supported platforms
The concepts of syslog-ng
The philosophy of syslog-ng
Logging with syslog-ng
Modes of operation
Global objects
Timezones and daylight saving
Versions and releases of syslog-ng Premium Edition
Licensing
GPL and LGPL licenses
High availability support
The structure of a log message
Message representation in syslog-ng PE
Structuring macros, metadata, and other value-pairs
Things to consider when forwarding messages between syslog-ng PE hosts
Using syslog-ng PE with NFS or CIFS (or SMB) file system for log files
Installing syslog-ng PE
Prerequisites to installing syslog-ng PE
Security-enhanced Linux: grsecurity, SELinux
Installing syslog-ng PE on RPM-based platforms (Red Hat, SUSE, AIX)
Using syslog-ng PE on SELinux
Installing syslog-ng PE on Debian-based platforms
Installing syslog-ng in Docker
Installing syslog-ng using the .run installer
The syslog-ng PE quick-start guide
Installing syslog-ng PE in client or relay mode
Installing syslog-ng PE in server mode
Installing syslog-ng PE without user-interaction
Upgrading syslog-ng PE
Upgrading from syslog-ng PE 7.0.x to version 7
Upgrading from syslog-ng PE 6.0.x to version 7
Upgrading syslog-ng PE to other package versions
Upgrading from syslog-ng PE to syslog-ng OSE
Upgrade from syslog-ng OSE to syslog-ng PE
Upgrading from complete syslog-ng PE to client setup version of syslog-ng PE
Upgrading the sql() source of syslog-ng PE
Uninstalling syslog-ng PE
Configuring Microsoft SQL Server to accept logs from syslog-ng
Configuring syslog-ng on client hosts
Configuring syslog-ng on server hosts
Configuring syslog-ng relays
Managing and checking syslog-ng PE service on Linux
The syslog-ng PE configuration file
Location of the syslog-ng configuration file
The configuration syntax in detail
Notes about the configuration syntax
Defining configuration objects inline
Using channels in configuration objects
Global and environmental variables
Logging configuration changes
Modules in syslog-ng Premium Edition (syslog-ng PE)
Managing complex syslog-ng configurations
Collecting log messages — sources and source drivers
Including configuration files
Reusing configuration blocks
Generating configuration blocks from a script
Python code in external files
Logging from your Python code
How sources work
default-network-drivers: Receive and parse common syslog messages
internal: Collecting internal messages
file: Collecting messages from text files
google-pubsub: collecting messages from the Google Pub/Sub messaging service
Sending and storing log messages — destinations and destination drivers
Prerequisites
Limitations
Supported platforms
Declaration
The Google Pub/Sub message format in syslog-ng PE
wildcard-file: Collecting messages from multiple text files
linux-audit: Collecting messages from Linux audit logs
mssql, oracle, sql: collecting messages from an SQL database
The contents of the Google Pub/Sub Message body on the syslog-ng Premium Edition (syslog-ng PE) side
The contents of the Google Pub/Sub Message attributes on the syslog-ng PE (syslog-ng PE) side
Processing incoming message contents in raw message format and in .JSON format
google-pubsub() source options
Preventing message duplication resulting from the At-Least-Once delivery behavior
Error messages you may encounter while using the google-pubsub() source
mssql(), oracle(), and sql() source options
Customizing mssql() queries
Configuring TLS encryption for MSSQL servers
Possible connection errors between the MSSQL server (2019) and syslog-ng PE 7 LTS
network: Collecting messages using the RFC3164 protocol (network() driver)
office365: Fetching logs from Office 365
Configuring Office 365 to permit fetching logs
office365() source options
Troubleshooting audit logging in Office 365
osquery: Collect and parse osquery result logs
pipe: Collecting messages from named pipes
program: Receiving messages from external applications
python: writing server-style Python sources
python-fetcher: writing fetcher-style Python sources
snmptrap: Read Net-SNMP traps
syslog: Collecting messages using the IETF syslog protocol (syslog() driver)
system: Collecting the system-specific log messages of a platform
systemd-journal: Collecting messages from the systemd-journal system log storage
systemd-syslog: Collecting systemd messages using a socket
tcp, tcp6,udp, udp6: Collecting messages from remote hosts using the BSD syslog protocol
udp-balancer: Receiving UDP messages at very high rate
unix-stream, unix-dgram: Collecting messages from UNIX domain sockets
windowsevent: Collecting Windows event logs
elasticsearch2>: Sending messages directly to Elasticsearch version 2.0 or higher (DEPRECATED)
Routing messages: log paths, flags, and filters
Prerequisites
How syslog-ng PE interacts with Elasticsearch
Client modes
Elasticsearch2 destination options (DEPRECATED)
elasticsearch-http: Sending messages to Elasticsearch HTTP Event Collector
file: Storing messages in plain-text files
google_pubsub(): Sending logs to the Google Cloud Pub/Sub messaging service
Limitations
Configuring the google_pubsub() destination
google_pubsub() destination options
Available endpoints for the google_pubsub() destination
Error messages you may encounter while using the google_pubsub() destination
hdfs: Storing messages on the Hadoop Distributed File System (HDFS)
Prerequisites
How syslog-ng PE interacts with HDFS
Storing messages with MapR-FS
Kerberos authentication with syslog-ng hdfs() destination
HDFS destination options
http: Posting messages over HTTP
kafka(): Publishing messages to Apache Kafka (Java implementation) (DEPRECATED)
kafka-c(): Publishing messages to Apache Kafka using the librdkafka client (C implementation)
kafka-c(): Prerequisites and limitations
kafka-c(): Shifting from the Java implementation to the C implementation
kafka-c(): Flow control in syslog-ng PE and the Kafka client
Options of the kafka-c() destination
logstore: Storing messages in encrypted files
mongodb: Storing messages in a MongoDB database
network: Sending messages to a remote log server using the RFC3164 protocol (network() driver)
pipe: Sending messages to named pipes
program: Sending messages to external applications
python: writing custom Python destinations
sentinel(): Sending logs to the Microsoft Azure Sentinel cloud
Configuring the sentinel() destination to send logs to the Microsoft Azure Sentinel cloud
snmp: Sending SNMP traps
smtp: Generating SMTP messages (email) from logs
splunk-hec: Sending messages to Splunk HTTP Event Collector
sql(): Storing messages in an SQL database
Getting the required credentials to configure syslog-ng PE as a Data Connector for Microsoft Azure Sentinel
Log types
sentinel() destination options
Using the sql() driver with an Oracle database
Using the sql() driver with a Microsoft SQL database
The way syslog-ng PE interacts with the database
sql() destination options
stackdriver: Sending logs to the Google Stackdriver cloud
syslog: Sending messages to a remote logserver using the IETF-syslog protocol
syslog-ng(): Forward logs to another syslog-ng node
tcp, tcp6, udp, udp6: Sending messages to a remote log server using the legacy BSD-syslog protocol (tcp(), udp() drivers)
unix-stream, unix-dgram: Sending messages to UNIX domain sockets
usertty: Sending messages to a user terminal — usertty() destination
Client-side failover
Log paths
Managing incoming and outgoing messages with flow-control
Using the disk-buffer option and memory buffering
Global options of syslog-ng PE
TLS-encrypted message transfer
Enabling the reliable disk-buffer option
Enabling the normal disk-buffer option
How to get information about disk-buffer files
Filters
Information about disk-buffer files
Getting the list of disk-buffer files
Getting the status information of disk-buffer files
Printing the content of disk-buffer files
Orphan disk-buffer files
How to process messages from an orphan disk-buffer file using a separate syslog-ng PE instance
How to empty disk-buffer files
Enabling memory buffering
About disk queue files
Using filters
Combining filters with boolean operators
Comparing macro values in filters
Using wildcards, special characters, and regular expressions in filters
Tagging messages
Filter functions
Dropping messages
Secure logging using TLS
Encrypting log messages with TLS
Mutual authentication using TLS
Password-protected keys
TLS options
Advanced Log Transport Protocol
Reliability and minimizing the loss of log messages
Introduction
Flow control, no disk-buffer option, no ALTP
Flow control, normal disk-buffer option, no ALTP
Flow control, reliable disk-buffer option, no ALTP
Flow control, reliable disk-buffer option, ALTP
Deciding which loss prevention mechanism to apply
Manipulating messages
Customizing message format using macros and templates
parser: Parse and segment structured messages
Formatting messages, filenames, directories, and tablenames
Templates and macros
Date-related macros
Hard versus soft macros
Macros of syslog-ng PE
Using template functions
Template functions of syslog-ng PE
Modifying the on-the-wire message format
Modifying messages using rewrite rules
Replacing message parts
Setting message fields to specific values
Unsetting message fields
Creating custom SDATA fields
Setting multiple message fields to specific values
Conditional rewrites
Anonymizing credit card numbers
Regular expressions
Parsing syslog messages
Parsing messages with comma-separated and similar values
Parsing key=value pairs
JSON parser
XML parser
Parsing dates and timestamps
Cisco Parser
Linux audit parser
Python parser
Parsing enterprise-wide message model (EWMM) messages
Sudo parser
iptables parser
Processing message content with a pattern database
Classifying log messages
Using pattern databases
Correlating log messages using pattern databases
Triggering actions for identified messages
Creating pattern databases
Correlating log messages
Enriching log messages with external data
Monitoring statistics and metrics of syslog-ng
Metrics and counters of syslog-ng PE
Log statistics from the internal() source
The monitoring() source
Multithreading and scaling in syslog-ng PE
Multithreading concepts of syslog-ng PE
Configuring multithreading
Optimizing multithreaded performance
Troubleshooting syslog-ng
Possible causes of losing log messages
Creating syslog-ng core files
Collecting debugging information with strace, truss, or tusc
Running a failure script
Stopping syslog-ng
Reporting bugs and finding help
Error messages
Best practices and examples
General recommendations
Handling large message load
Using name resolution in syslog-ng
Collecting logs from chroot
Configuring log rotation
Load balancing logs between multiple destinations
The syslog-ng manual pages
Glossary
Multithreading and scaling in syslog-ng PE
Multithreading and scaling in syslog-ng PE
Multithreading concepts of syslog-ng PE
This section is a brief overview on how syslog-ng PE works in multithreaded mode. It is mainly for illustration purposes: the concept has been somewhat simplified and may not completely match reality.
NOTE: The way syslog-ng PE uses multithreading may change in future releases. The current documentation applies to version 7.
syslog-ng PE always uses multiple threads:
-
A main thread that is always running
-
A number of worker threads that process the messages. You can influence the behavior of worker threads using the threaded() option and the --worker-threads command-line option.
-
Some other, special threads for internal functionalities. For example, certain destinations run in a separate thread, independently of the multithreading (threaded()) and --worker-threads settings of syslog-ng PE.
The maximum number of worker threads syslog-ng PE uses is the number of CPUs or cores in the host running syslog-ng PE (up to 64). You can limit this value using the --worker-threads command-line option that sets the maximum total number of threads syslog-ng PE can use, including the main syslog-ng PE thread. However, the --worker-threads option does not affect the supervisor of syslog-ng PE. The supervisor is a separate process (see The syslog-ng manual page), but certain operating systems might display it as a thread. In addition, certain destinations always run in a separate thread, independently of the multithreading (threaded()) and --worker-threads settings of syslog-ng PE.
When an event requiring a new thread occurs (for example, syslog-ng PE receives new messages, or a destination becomes available), syslog-ng PE tries to start a new thread. If there are no free threads, the task waits until a thread finishes its task and becomes available. There are two types of worker threads:
-
Reader threads read messages from a source (as many as possible, but limited by the log-fetch-limit() and log-iw-size() options. The thread then processes these messages, that is, performs filtering, rewriting and other tasks as necessary, and puts the log message into the queue of the destination. If the destination does not have a queue (for example, usertty), the reader thread sends the message to the destination, without the interaction of a separate writer thread.
-
Writer threads take the messages from the queue of the destination and send them to the destination, that is, write the messages into a file, or send them to the syslog server over the network. The writer thread starts to process messages from the queue only if the destination is writable, and there are enough messages in the queue, as set in the flush-lines() and the flush-timeout() options. Writer threads stop processing messages when the destination becomes unavailable, or there are no more messages in the queue.
Sources and destinations affected by multithreading
The following list describes which sources and destinations can use multiple threads. Changing the --worker-threads command-line option changes the number of threads available to these sources and destinations.
-
The tcp and syslog(tcp) sources can process independent connections in separate threads. The number of independent connections is limited by the max-connections() option of the source. Separate sources are processed by separate thread, for example, if you have two separate tcp sources defined that receive messages on different IP addresses or port, syslog-ng PE will use separate threads for these sources even if they both have only a single active connection.
-
The udp, file, and pipe sources use a single thread for every source statement.
-
The udp-balancer source uses a thread for each listener configured in its listeners() option.
-
The tcp, syslog, and pipe destinations use a single thread for every destination.
-
The file destination uses a single thread for writing the destination file, but may use a separate thread for each destination file if the filename includes macros.
Sources and destinations not affected by multithreading
The following list describes sources and destinations that use a separate thread even if you disable multithreading in syslog-ng PE, in addition to the limit set in the --worker-threads command-line option.
-
The logstore destination uses separate threads for writing the messages from the journal to the logstore files, and also for timestamping. These threads are independent from the setting of the --worker-threads command-line option.
-
Every sql destination uses its own thread. These threads are independent from the setting of the --worker-threads command-line option.
-
The java destinations use one thread, even if there are multiple Java-based destinations configured. This thread is independent from the setting of the --worker-threads command-line option.
Configuring multithreading
Starting with version
-
Globally using the threaded(yes) option.
-
Separately for selected sources or destinations using the flags("threaded") option.
Example: Enabling multithreading
To enable multithreading globally, use the threaded option:
options {threaded(yes) ; };
To enable multithreading only for a selected source or destination, use the flags("threaded") option:
source s_tcp_syslog { network(ip(127.0.0.1) port(1999) flags("syslog-protocol", "threaded") ); };Optimizing multithreaded performance
Sources
File sources scale based on the number of files that the syslog-ng PE is reading. If there are 10 files all coming to the same source, then that source can use 10 threads, one thread for each file.
NOTE: When collecting log messages from multiple files, the file source is a wildcard-file() source.
TCP-based network sources scale based on the number of active connections. This means that if there are 10 incoming connections all coming to the same source, then that source can use 10 threads, one thread for each connection.
NOTE: UDP-based network sources do not scale by themselves because they always use a single thread. If you want to handle a large number of UDP connections, it is best to configure a subset of your clients to send the messages to a different port of your syslog-ng server, and use separate source definitions for each port.
Figure 43: How multithreading works — sources
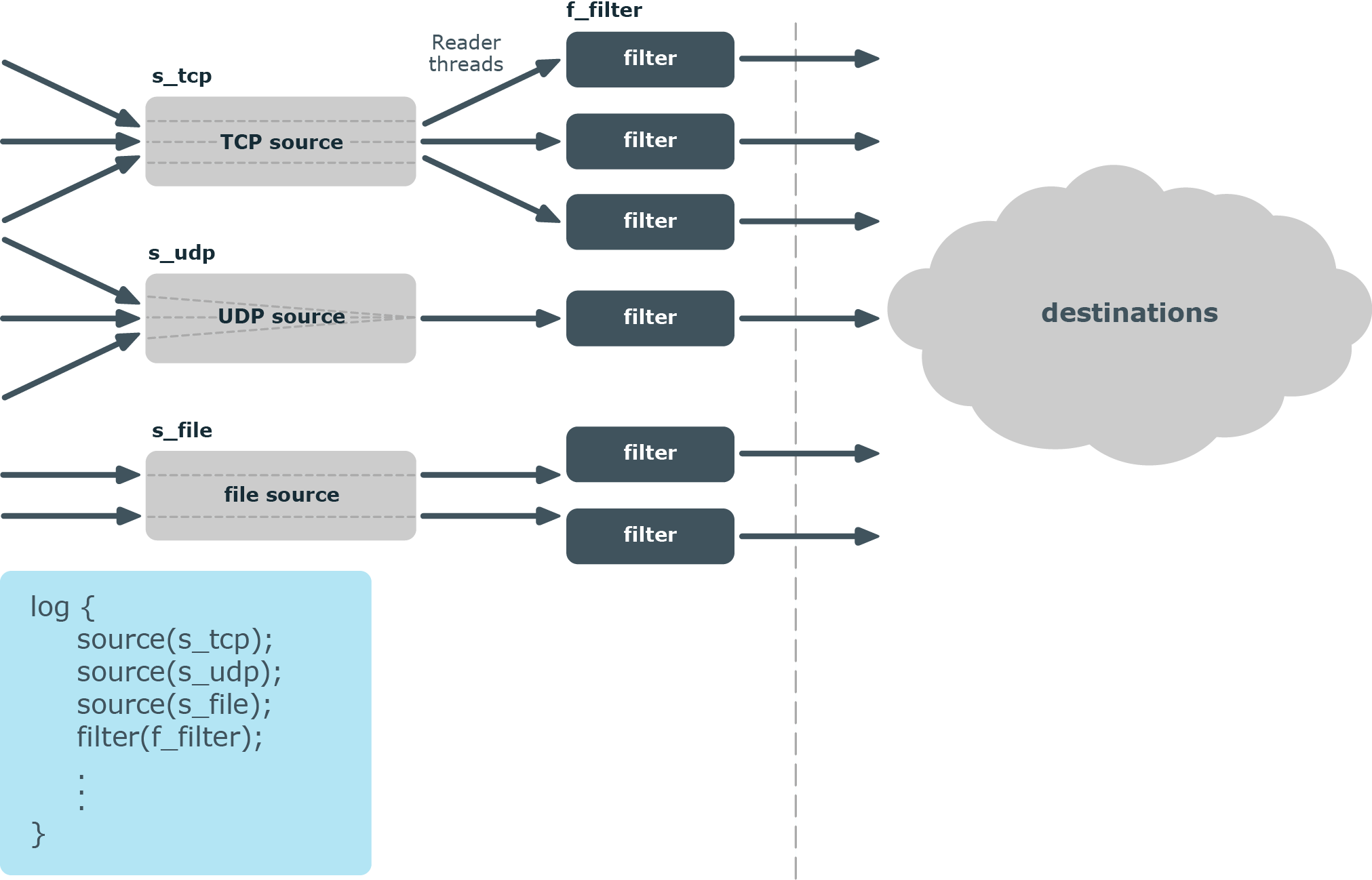
Message processors
Message processors — such as filters, rewrite rules, and parsers — are executed by the reader thread in a sequential manner.
For example, if you have a log path that defines two sources and a filter, the filter will be performed by the source1 reader thread when log messages come from source1, and by the source2 reader thread when log messages come from source2. This means that if log messages come from both source1 and source2, they will both have a reader thread and that way filtering will be performed simultaneously.
NOTE: This is not true for PatternDB because it uses message correlation. When using PatternDB, it runs in only one thread at a time, and this significantly decreases performance.
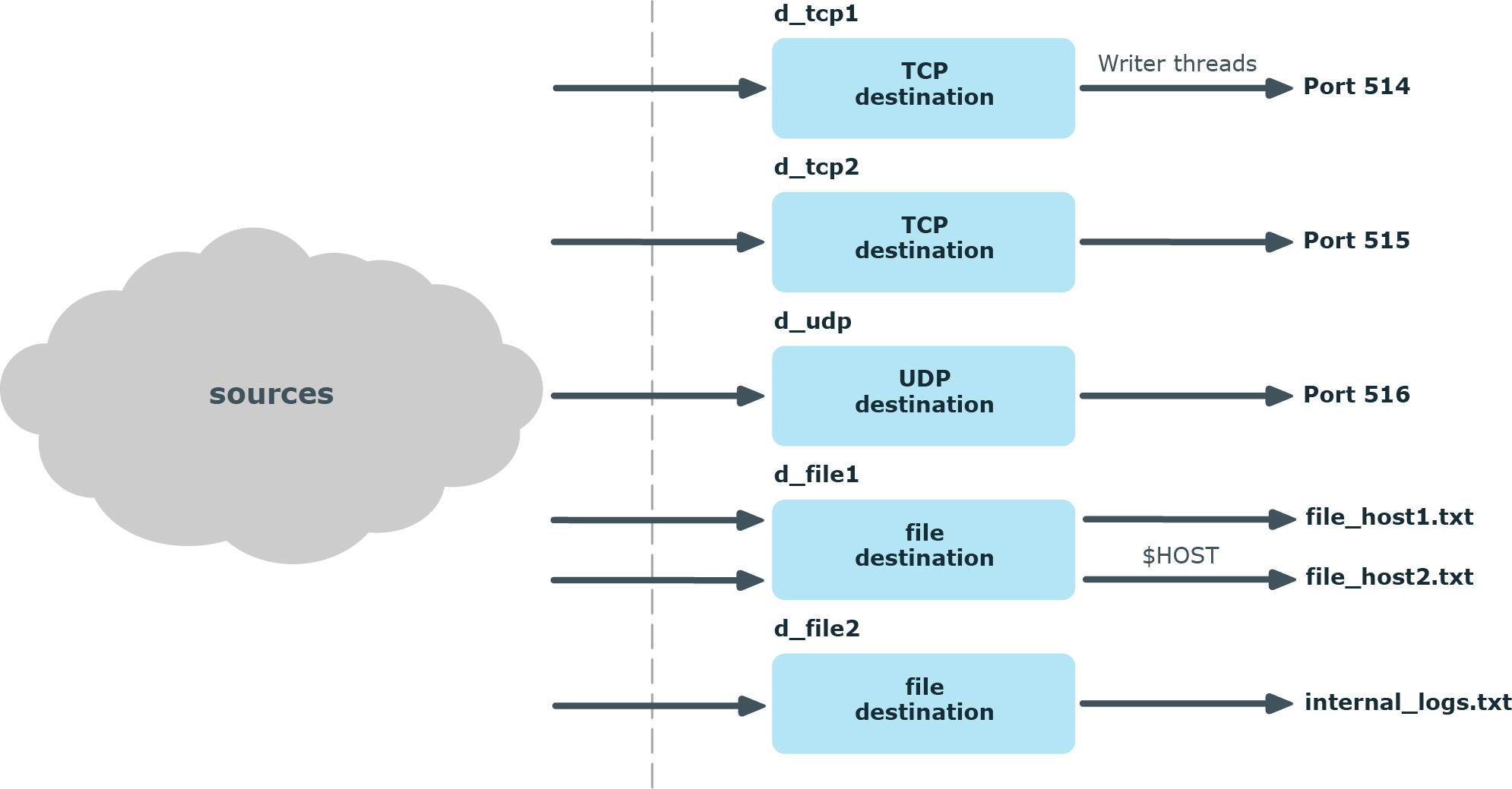
Destinations
In syslog-ng, every destination has a writer thread. To improve scaling on the destination side, use multiple destinations instead of one.
For example, when sending messages to a syslog-ng server, you can use multiple connections to the server if you configure the syslog-ng server to receive messages on multiple ports, and configure the clients to use both ports.
When writing the log messages to files, use macros in the filename to split the messages to separate files (for example, using the ${HOST} macro). Files with macros in their filenames are processed in separate writer threads.
Figure 44: How multithreading works — destinations