
Chapter 16. Processing message content with a pattern database
The syslog-ng application can compare the contents of the received log messages to predefined message patterns. By comparing the messages to the known patterns, syslog-ng is able to identify the exact type of the messages, and sort them into message classes. The message classes can be used to classify the type of the event described in the log message. The message classes can be customized, and for example can label the messages as user login, application crash, file transfer, and so on events.
To find the pattern that matches a particular message, syslog-ng uses a method called longest prefix match radix tree. This means that syslog-ng creates a tree structure of the available patterns, where the different characters available in the patterns for a given position are the branches of the tree.
To classify a message, syslog-ng selects the first character of the message (the text of message, not the header), and selects the patterns starting with this character, other patterns are ignored for the rest of the process. After that, the second character of the message is compared to the second character of the selected patterns. Again, matching patterns are selected, and the others discarded. This process is repeated until a single pattern completely matches the message, or no match is found. In the latter case, the message is classified as unknown, otherwise the class of the matching pattern is assigned to the message.
To make the message classification more flexible and robust, the patterns can contain pattern parsers: elements that match on a set of characters. For example, the NUMBER parser matches on any integer or hexadecimal number (for example 1, 123, 894054, 0xFFFF, and so on). Other pattern parsers match on various strings and IP addresses. For the details of available pattern parsers, see the section called “Using pattern parsers”.
The functionality of the pattern database is similar to that of the logcheck project, but it is much easier to write and maintain the patterns used by syslog-ng, than the regular expressions used by logcheck. Also, it is much easier to understand syslog-ng pattens than regular expressions.
Pattern matching based on regular expressions is computationally very intensive, especially when the number of patterns increases. The solution used by syslog-ng can be performed real-time, and is independent from the number of patterns, so it scales much better. The following patterns describe the same message: Accepted password for bazsi from 10.50.0.247 port 42156 ssh2
A regular expression matching this message from the logcheck project: Accepted (gssapi(-with-mic|-keyex)?|rsa|dsa|password|publickey|keyboard-interactive/pam) for [^[:space:]]+ from [^[:space:]]+ port [0-9]+( (ssh|ssh2))?
A syslog-ng database pattern for this message: Accepted @QSTRING:auth_method: @ for@QSTRING:username: @from @QSTRING:client_addr: @port @NUMBER:port:@ ssh2
For details on using pattern databases to classify log messages, see the section called “Using pattern databases”.
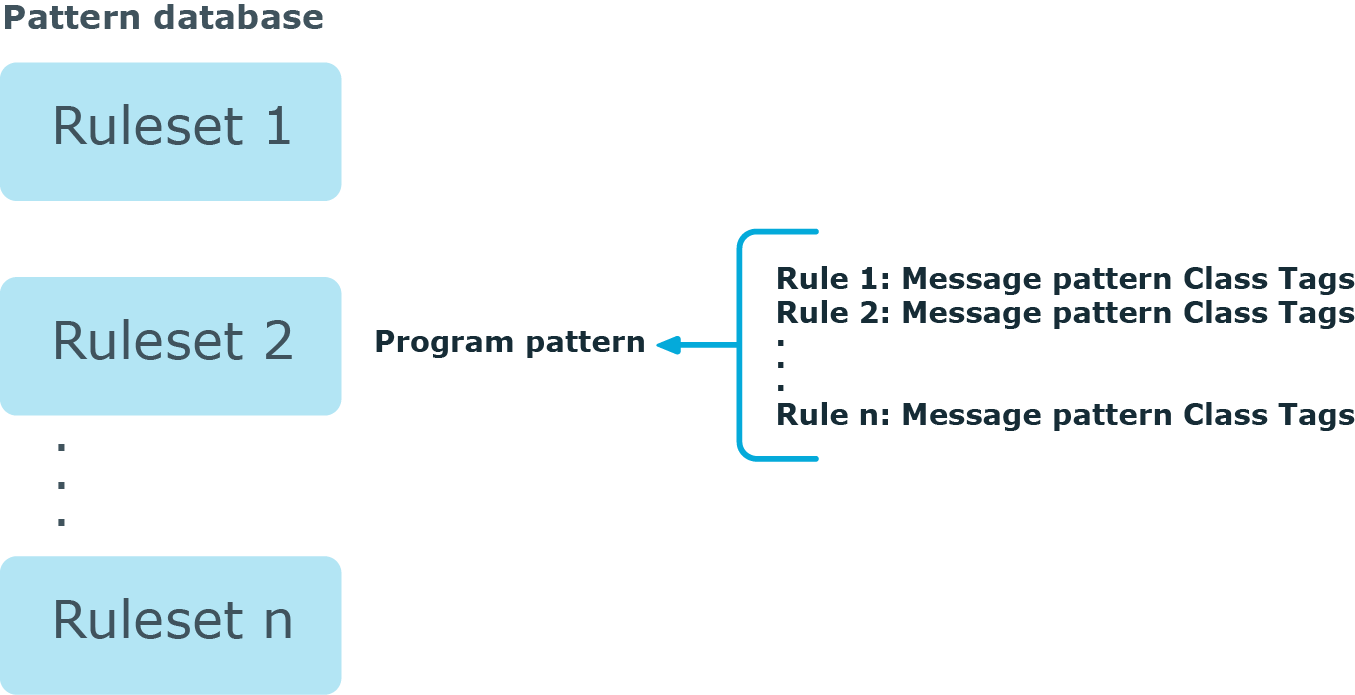
The pattern database is organized as follows:
-
The pattern database consists of rulesets. A ruleset consists of a Program Pattern and a set of rules: the rules of a ruleset are applied to log messages if the name of the application that sent the message matches the Program Pattern of the ruleset. The name of the application (the content of the ${PROGRAM} macro) is compared to the Program Patterns of the available rulesets, and then the rules of the matching rulesets are applied to the message.
-
The Program Pattern can be a string that specifies the name of the appliation or the beginning of its name (for example, to match for sendmail, the program pattern can be sendmail, or just send), and the Program Pattern can contain pattern parsers. Note that pattern parsers are completely independent from the syslog-ng parsers used to segment messages. Additionally, every rule has a unique identifier: if a message matches a rule, the identifier of the rule is stored together with the message.
-
Rules consist of a message pattern and a class. The Message Pattern is similar to the Program Pattern, but is applied to the message part of the log message (the content of the ${MESSAGE} macro). If a message pattern matches the message, the class of the rule is assigned to the message (for example, Security, Violation, and so on).
-
Rules can also contain additional information about the matching messages, such as the description of the rule, an URL, name-value pairs, or free-form tags.
-
Patterns can consist of literals (keywords, or rather, keycharacters) and pattern parsers.
NOTE: If the ${PROGRAM} part of a message is empty, rules with an empty Program Pattern are used to classify the message.
If the same Program Pattern is used in multiple rulesets, the rules of these rulesets are merged, and every rule is used to classify the message. Note that message patterns must be unique within the merged rulesets, but the currently only one ruleset is checked for uniqueness.


The followings describe how patterns work. This information applies to program patterns and message patterns alike, even though message patterns are used to illustrate the procedure.
Patterns can consist of literals (keywords, or rather, keycharacters) and pattern parsers. Pattern parsers attempt to parse a sequence of characters according to certain rules.
|
|
NOTE:
Wildcards and regular expressions cannot be used in patterns. The |
When a new message arrives, syslog-ng attempts to classify it using the pattern database. The available patterns are organized alphabetically into a tree, and syslog-ng inspects the message character-by-character, starting from the beginning. This approach ensures that only a small subset of the rules must be evaluated at any given step, resulting in high processing speed. Note that the speed of classifying messages is practically independent from the total number of rules.
For example, if the message begins with the Apple string, only patterns beginning with the character A are considered. In the next step, syslog-ng selects the patterns that start with Ap, and so on, until there is no more specific pattern left.
Note that literal matches take precedence over pattern parser matches: if at a step there is a pattern that matches the next character with a literal, and another pattern that would match it with a parser, the pattern with the literal match is selected. Using the previous example, if at the third step there is the literal pattern Apport and a pattern parser Ap@STRING@, the Apport pattern is matched. If the literal does not match the incoming string (for example, Apple), syslog-ng attempts to match the pattern with the parser. However, if there are two or more parsers on the same level, only the first one will be applied, even if it does not perfectly match the message.
If there are two parsers at the same level (for example, Ap@STRING@ and Ap@QSTRING@), it is random which pattern is applied (technically, the one that is loaded first). However, if the selected parser cannot parse at least one character of the message, the other parser is used. But having two different parsers at the same level is extremely rare, so the impact of this limitation is much less than it appears.
Artificial ignorance is a method to detect anomalies. When applied to log analysis, it means that you ignore the regular, common log messages - these are the result of the regular behavior of your system, and therefore are not too interesting. However, new messages that have not appeared in the logs before can sign important events, and should be therefore investigated. "By definition, something we have never seen before is anomalous" (Marcus J. Ranum).
The syslog-ng application can classify messages using a pattern database: messages that do not match any pattern are classified as unknown. This provides a way to use artificial ignorance to review your log messages. You can periodically review the unknown messages — syslog-ng can send them to a separate destination, and add patterns for them to the pattern database. By reviewing and manually classifying the unknown messages, you can iteratively classify more and more messages, until only the really anomalous messages show up as unknown.
Obviously, for this to work, a large number of message patterns are required. The radix-tree matching method used for message classification is very effective, can be performed very fast, and scales very well. Basically the time required to perform a pattern matching is independent from the number of patterns in the database. For sample pattern databases, see the section called “Downloading sample pattern databases”.
Using pattern databases
To classify messages using a pattern database, include a db-parser() statement in your syslog-ng configuration file using the following syntax:
Declaration:
parser <identifier> {db-parser(file("<database_filename>"));};
Note that using the parser in a log statement only performs the classification, but does not automatically do anything with the results of the classification.
Example 16.1. Defining pattern databases
The following statement uses the database located at /opt/syslog-ng/var/db/patterndb.xml.
parser pattern_db {
db-parser(
file("/opt/syslog-ng/var/db/patterndb.xml")
);
};
To apply the patterns on the incoming messages, include the parser in a log statement:
log {
source(s_all);
parser(pattern_db);
destination( di_messages_class);
};Example 16.2. Using classification results
The following destination separates the log messages into different files based on the class assigned to the pattern that matches the message (for example Violation and Security type messages are stored in a separate file), and also adds the ID of the matching rule to the message:
destination di_messages_class {
file("/var/log/messages-${.classifier.class}"
template("${.classifier.rule_id};${S_UNIXTIME};${SOURCEIP};${HOST};${PROGRAM};${PID};${MSG}\n")
template-escape(no)
);
};For details on how to create your own pattern databases see the section called “The syslog-ng pattern database format”.
The results of message classification and parsing can be used in custom filters and templates, for example, in file and database templates. The following built-in macros allow you to use the results of the classification:
Example 16.3. Using classification results for filtering messages
To filter on a specific message class, create a filter that checks the .classifier_class macro, and use this filter in a log statement.
filter fi_class_violation {
match("violation"
value(".classifier.class")
type("string")
);
};log {
source(s_all);
parser(pattern_db);
filter(fi_class_violation);
destination(di_class_violation);
};
Filtering on the unknown class selects messages that did not match any rule of the pattern database. Routing these messages into a separate file allows you to periodically review new or unknown messages.
To filter on messages matching a specific classification rule, create a filter that checks the .classifier.rule_id macro. The unique identifier of the rule (for example e1e9c0d8-13bb-11de-8293-000c2922ed0a) is the id attribute of the rule in the XML database.
filter fi_class_rule {
match("e1e9c0d8-13bb-11de-8293-000c2922ed0a"
value(".classifier.rule_id")
type("string")
);
};Pattern database rules can assign tags to messages. These tags can be used to select tagged messages using the tags() filter function.
The message-segments parsed by the pattern parsers can also be used as macros as well. To accomplish this, you have to add a name to the parser, and then you can use this name as a macro that refers to the parsed value of the message.
Example 16.4. Using pattern parsers as macros
For example, you want to parse messages of an application that look like "Transaction: <type>.", where <type> is a string that has different values (for example refused, accepted, incomplete, and so on). To parse these messages, you can use the following pattern:
'Transaction: @ESTRING::.@'
Here the @ESTRING@ parser parses the message until the next full stop character. To use the results in a filter or a filename template, include a name in the parser of the pattern, for example:
'Transaction: @ESTRING:TRANSACTIONTYPE:.@'
After that, add a custom template to the log path that uses this template. For example, to select every accepted transaction, use the following custom filter in the log path:
match("accepted" value("TRANSACTIONTYPE"));|
|
NOTE:
The above macros can be used in database columns and filename templates as well, if you create custom templates for the destination or logspace. Use a consistent naming scheme for your macros, for example, |
To simplify the building of pattern databases, Balabit has released (and will continue to release) sample databases. You can download sample pattern databases from the PatternDB GitHub page.
Note that these pattern databases are only samples and experimental databases. They are not officially supported, and may or may not work in your environment.
The syslog-ng pattern databases are available under the Creative Commons Attribution-Share Alike 3.0 (CC by-SA) license. This includes every pattern database written by community contributors or the Balabit staff. It means that:
-
You are free to use and modify the patterns for your needs.
-
If you redistribute the pattern databases, you must distribute your modifications under the same license.
-
If you redistribute the pattern databases, you must make it obvious that the source of the original syslog-ng pattern databases is the PatternDb GitHub page.
For legal details, the full text of the license is available here.
If you create patterns that are not available in the GitHub repository, consider sharing them with us and the syslog-ng community, and send them to the syslog-ng mailing list, or to the following e-mail address:<patterndb@balabit.com>
Correlating log messages
The syslog-ng PE application is able to correlate log messages identified using pattern databases.
Log messages are supposed to describe events, but applications often separate information about a single event into different log messages. For example, the Postfix e-mail server logs the sender and recipient addresses into separate log messages, or in case of an unsuccessful login attempt, the OpenSSH server sends a log message about the authentication failure, and the reason of the failure in the next message.
Of course, messages that are not so directly related can be correlated as well, for example, login-logout messages, and so on.
To correlate log messages, syslog-ng PE uses the pattern database to add messages into message-groups called contexts. A context consists of a series of log messages that are related to each other in some way, for example, the log messages of an SSH session can belong to the same context. As new messages come in, they may be added to a context. Also, when an incoming message is identified it can trigger actions to be performed, for example, generate a new message that contains all the important information that was stored previously in the context. (For details on triggering actions and generating messages, see the section called “Triggering actions for identified messages”.)
There are two attributes for pattern database rules that determine if a message matching the rule is added to a context: context-scope and context-id. The context-scope attribute acts as an early filter, selecting messages sent by the same process (${HOST}${PROGRAM}${PID} is identical), application (${HOST}${PROGRAM} is identical), or host, while the context-id actually adds the message to the context specified in the id. The context-id can be a simple string, or can contain macros or values extracted from the log messages for further filtering.
|
|
NOTE:
Message contexts are persistent and are not lost when syslog-ng PE is reloaded (SIGHUP), but are lost when syslog-ng PE is restarted. |
Another parameter of a rule is the context-timeout attribute, which determines how long a context is stored, that is, how long syslog-ng PE waits for related messages to arrive. Note the following points about timeout values:
-
When a new message is added to a context, syslog-ng PE will restart the timeout using the
context-timeoutset for the new message. -
When calculating if the timeout has already expired or not, syslog-ng PE uses the timestamps of the incoming messages, not system time elapsed between receiving the two messages (unless the messages do not include a timestamp, or the
keep-timestamp(no)option is set). That way syslog-ng PE can be used to process and correlate already existing log messages offline. However, the timestamps of the messages must be in chronological order (that is, a new message cannot be older than the one already processed), and if a message is newer than the current system time (that is, it seems to be coming from the future), syslog-ng PE will replace its timestamp with the current system time.Example 16.5. How syslog-ng PE calculates
context-timeoutConsider the following two messages:
<38>1990-01-01T14:45:25 customhostname program6[1234]: program6 testmessage <38>1990-01-01T14:46:25 customhostname program6[1234]: program6 testmessage
If the
context-timeoutis 10 seconds and syslog-ng PE receives the messages within 1 sec, the timeout event will occour immediately, because the difference of the two timestamp (60 sec) is larger than the timeout value (10 sec).
-
Avoid using unnecessarily long timeout values on high-traffic systems, as storing the contexts for many messages can require considerable memory. For example, if two related messages usually arrive within seconds, it is not needed to set the timeout to several hours.
Example 16.6. Using message correlation
<rule xml:id="..." context-id="ssh-session" context-timeout="86400" context-scope="process"> <patterns> <pattern>Accepted @ESTRING:usracct.authmethod: @for @ESTRING:usracct.username: @from @ESTRING:usracct.device: @port @ESTRING:: @@ANYSTRING:usracct.service@</pattern> </patterns>... </rule>
For details on configuring message correlation, see the description of the context-id, context-timeout, and context-scope attributes of pattern database rules.
When using the <value> element in pattern database rules together with message correlation, you can also refer to fields and values of earlier messages of the context by adding the @<distance-of-referenced-message-from-the-current> suffix to the macro. For example, if there are three log messages in a context, and you are creating a generated message for the third log message, the ${HOST}@1 expression refers to the host field of the current (third) message in the context, the ${HOST}@2 expression refers to the host field of the previous (second) message in the context, ${PID}@3 to the PID of the first message, and so on. For example, the following message can be created from SSH login/logout messages (for details on generating new messages, see the section called “Triggering actions for identified messages”): An SSH session for ${SSH_USERNAME}@1 from ${SSH_CLIENT_ADDRESS}@2 closed. Session lasted from ${DATE}@2 to ${DATE}.
|
|
Caution:
When referencing an earlier message of the context, always enclose the field name between braces, for example, |

|
|
NOTE:
To use a literal |
Example 16.7. Referencing values from an earlier message
The following action can be used to log the length of an SSH session (the time difference between a login and a logout message in the context):
<actions> <action> <message> <values> <value name="MESSAGE">An SSH session for ${SSH_USERNAME}@1 from ${SSH_CLIENT_ADDRESS}@2 closed. Session lasted from ${DATE}@2 ${DATE} </value> </values> </message> </action></actions>Triggering actions for identified messages
The syslog-ng PE application is able to generate (trigger) messages automatically if certain events occur, for example, a specific log message is received, or the correlation timeout of a message expires. Basically, you can define messages for every pattern database rule that are emitted when a message matching the rule is received. Triggering messages is often used together with message correlation, but can also be used separately.
The generated message is injected into the same place where the db-parser() statement is referenced in the log path. To post the generated message into the internal() source instead, use the inject-mode() option in the definition of the parser.
Example 16.8. Sending triggered messages to the internal() source
To send the generated messages to the internal source, use the inject-mode(internal) option:
parser p_db {db-parser(
file("mypatterndbfile.xml")
inject-mode(internal)
);};
To inject the generated messages where the pattern database is referenced, use the inject-mode(pass-through) option:
parser p_db {db-parser(
file("mypatterndbfile.xml")
inject-mode(pass-through)
);}; The generated message must be configured in the pattern database rule. It is possible to create an entire message, use macros and values extracted from the original message with pattern database, and so on.
Example 16.9. Generating messages for pattern database matches
When inserted in a pattern database rule, the following example generates a message when a message matching the rule is received.
<actions> <action> <message> <values> <value name="MESSAGE">A log message from ${HOST} matched rule number $.classifier.rule_id</value> </values> </message> </action></actions>To inherit the properties and values of the triggering message, set the inherit-properties attribute of the <message> element to TRUE. That way the triggering log message is cloned, including name-value pairs and tags. If you set any values for the message in the <action> element, they will override the values of the original message.
Example 16.10. Generating messages with inherited values
The following action generates a message that is identical to the original message, but its $PROGRAM field is set to overriding-original-program-name
<actions> <action> <message inherit-properties='TRUE'> <values> <value name="PROGRAM">overriding-original-program-name</value> </values> </message> </action></actions>
For details on configuring actions, see the description of the pattern database format.
To limit when a message is triggered, use the condition attribute and specify a filter expression: the action will be executed only if the condition is met. For example, the following action is executed only if the message was sent by the host called myhost.
<action condition="'${HOST}' == 'example'">
You can use the same operators in the condition that can be used in filters. For details, see the section called “Comparing macro values in filters”.
The following action can be used to log the length of an SSH session (the time difference between a login and a logout message in the context):
<actions> <action> <message> <values> <value name="MESSAGE">An SSH session for ${SSH_USERNAME}@1 from ${SSH_CLIENT_ADDRESS}@2 closed. Session lasted from ${DATE}@2 ${DATE} </value> </values> </message> </action></actions>
Example 16.11. Actions based on the number of messages
The following example triggers different actions based on the number of messages in the context. This way you can check if the context contains enough messages for the event to be complete, and execute a different action if it does not.
<actions> <action condition='"$(context-length)" >= "4"'> <message> <values> <value name="PROGRAM">event</value> <value name="MESSAGE">Event complete</value> </values> </message> </action> <action condition='"$(context-length)" < "4"'> <message> <values> <value name="PROGRAM">error</value> <value name="MESSAGE">Error detected</value> </values> </message> </action></actions>
To perform an external action when a message is triggered, for example, to send the message in an e-mail, you have to route the generated messages to an external application using the program() destination.
Example 16.12. Sending triggered messages to external applications
The following sample configuration selects the triggered messages and sends them to an external script.
-
Set a field in the triggered message that is easy to identify and filter. For example:
<values> <value name="MESSAGE">A log message from ${HOST} matched rule number $.classifier.rule_id</value> <value name="TRIGGER">yes</value></values> -
Create a destination that will process the triggered messages.
destination d_triggers { program("/bin/myscript"; ); }; -
Create a filter that selects the triggered messages from the internal source.
filter f_triggers {match("yes" value ("TRIGGER") type(string));}; -
Create a log path that selects the triggered messages from the internal source and sends them to the script:
log { source(s_local); filter(f_triggers); destination(d_triggers); }; -
Create a script that will actually process the generated messages, for example:
#!/usr/bin/perl while (<>) { # body of the script to send emails, snmp traps, and so on }
Certain features of generating messages can be used only if message correlation is used as well. For details on correlating messages, see the section called “Correlating log messages”.
-
The syslog-ng PE application automatically fills the fields for the generated message based on the scope of the context, for example, the HOST and PROGRAM fields if the
context-scopeisprogram. -
When used together with message correlation, you can also refer to fields and values of earlier messages of the context by adding the
@<distance-of-referenced-message-from-the-current>suffix to the macro. For details, see the section called “Referencing earlier messages of the context”.Example 16.13. Referencing values from an earlier message
The following action can be used to log the length of an SSH session (the time difference between a login and a logout message in the context):
<actions> <action> <message> <values> <value name="MESSAGE">An SSH session for ${SSH_USERNAME}@1 from ${SSH_CLIENT_ADDRESS}@2 closed. Session lasted from ${DATE}@2 ${DATE} </value> </values> </message> </action></actions>
-
You can use the name-value pairs of other messages of the context. If you set the
inherit-propertiesattribute of the generated message tocontext, syslog-ng PE collects every name-value pair from each message stored in the context, and includes them in the generated message. This means that you can refer to a name-value pair without having to know which message of the context included it. If a name-value pair appears in multiple messages of the context, the value in the latest message will be used. To refer to an earlier value, use the@<distance-of-referenced-message-from-the-current>suffix format.<action> <message inherit-properties='context'>
Example 16.14. Using the
inherit-propertiesoptionFor example, if
inherit-propertiesis set tocontext, and you have a rule that collects SSH login and logout messages to the same context, you can use the following value to generate a message collecting the most important information form both messages, including the beginning and end date.<value name="MESSAGE">An SSH session for ${SSH_USERNAME} from ${SSH_CLIENT_ADDRESS} closed. Session lasted from ${DATE}@2 to $DATE pid: $PID.</value>The following is a detailed rule for this purpose.
<patterndb version='4' pub_date='2015-04-13'> <ruleset name='sshd' id='12345678'> <pattern>sshd</pattern> <rules> <!-- The pattern database rule for the first log message --> <rule provider='me' id='12347598' class='system' context-id="ssh-login-logout" context-timeout="86400" context-scope="process"> <!-- Note the context-id that groups together the relevant messages, and the context-timeout value that determines how long a new message can be added to the context --> <patterns> <pattern>Accepted @ESTRING:SSH.AUTH_METHOD: @for @ESTRING:SSH_USERNAME: @from @ESTRING:SSH_CLIENT_ADDRESS: @port @ESTRING:: @@ANYSTRING:SSH_SERVICE@</pattern> <!-- This is the actual pattern used to identify the log message. The segments between the @ characters are parsers that recognize the variable parts of the message - they can also be used as macros. --> </patterns> </rule> <!-- The pattern database rule for the fourth log message --> <rule provider='me' id='12347599' class='system' context-id="ssh-login-logout" context-scope="process"> <patterns> <pattern>pam_unix(sshd:session): session closed for user @ANYSTRING:SSH_USERNAME@</pattern> </patterns> <actions> <action> <message inherit-properties='context'> <values> <value name="MESSAGE">An SSH session for ${SSH_USERNAME} from ${SSH_CLIENT_ADDRESS} closed. Session lasted from ${DATE}@2 to $DATE pid: $PID.</value> <value name="TRIGGER">yes</value> <!-- This is the new log message that is generated when the logout message is received. The macros ending with @2 reference values of the previous message from the context. --> </values> </message> </action> </actions> </rule> </rules> </ruleset></patterndb>
-
It is possible to generate a message when the
context-timeoutof the original message expires and no new message is added to the context during this time. To accomplish this, include thetrigger="timeout"attribute in the action element:<action trigger="timeout">
Example 16.15. Sending alert when a client disappears
The following example shows how to combine various features of syslog-ng PE to send an e-mail alert if a client stops sending messages.
-
Configure your clients to send MARK messages periodically. It is enough to configure MARK messages for the destination that forwards your log messages to your syslog-ng PE server (
mark-mode(periodical)). -
On your syslog-ng PE server, create a pattern database rule that matches on the incoming MARK messages. In the rule, set the
context-scopeattribute tohost, and thecontext-timeoutattribute to a value that is higher than themark-freqvalue set on your clients (by default,mark-freqis 1200 seconds, so setcontext-timeoutat least to 1500 seconds, but you might want to use a higher value, depending on your environment). -
Add an action to this rule that sends you an e-mail alert if the
context-timeoutexpires, and the server does not receive a new MARK message (<action trigger="timeout">). -
On your syslog-ng PE server, use the pattern database in the log path that handles incoming log messages.
-