
Grundlage des Role Mining ist immer eine Clusteranalyse, bei Analyzer mit Hilfe eines mathematischen Algorithmus versucht, einzelne Cluster, also Identitäten mit ähnlichen Berechtigungen, zu finden. Dabei werden entweder hierarchische Strukturen gebildet oder vorgegebene Strukturen genutzt, die für den Aufbau eines eigenen Rollenmodells genutzt werden können.
Beim Role Mining versucht man allerdings nicht nur, einzelne Cluster zu finden und diese dann Geschäftsrollen zuzuweisen. Vielmehr ist es sinnvoll, direkt hierarchische Rollenstrukturen zu entwickeln, die dann über die gängigen Vererbungsmechanismen effizient nutzbar sind.
Automatisiertes Role Mining unterstützt der One Identity Manager durch zwei verschiedene Clusteranalyseverfahren, die sich durch die Berechnung der Abstände zwischen einzelnen Clustern unterscheiden. Auch die Verwendung von bereits vorhandenen Rollenstrukturen, beispielsweise organisatorische Strukturen aus ERP-Systemen, ist möglich. Mit Hilfe der Berechtigungsanalyse können diesen Rollensturkturen dann Berechtigungen zugewiesen werden. Zuletzt können Rollenstrukturen frei definiert und die Zuordnung von Berechtigungen und Identitäten an Hand der vorhandenen Berechtigungen manuell bewertet werden.
Abbildung 14: Clusteranalyse-Verfahren im Analyzer
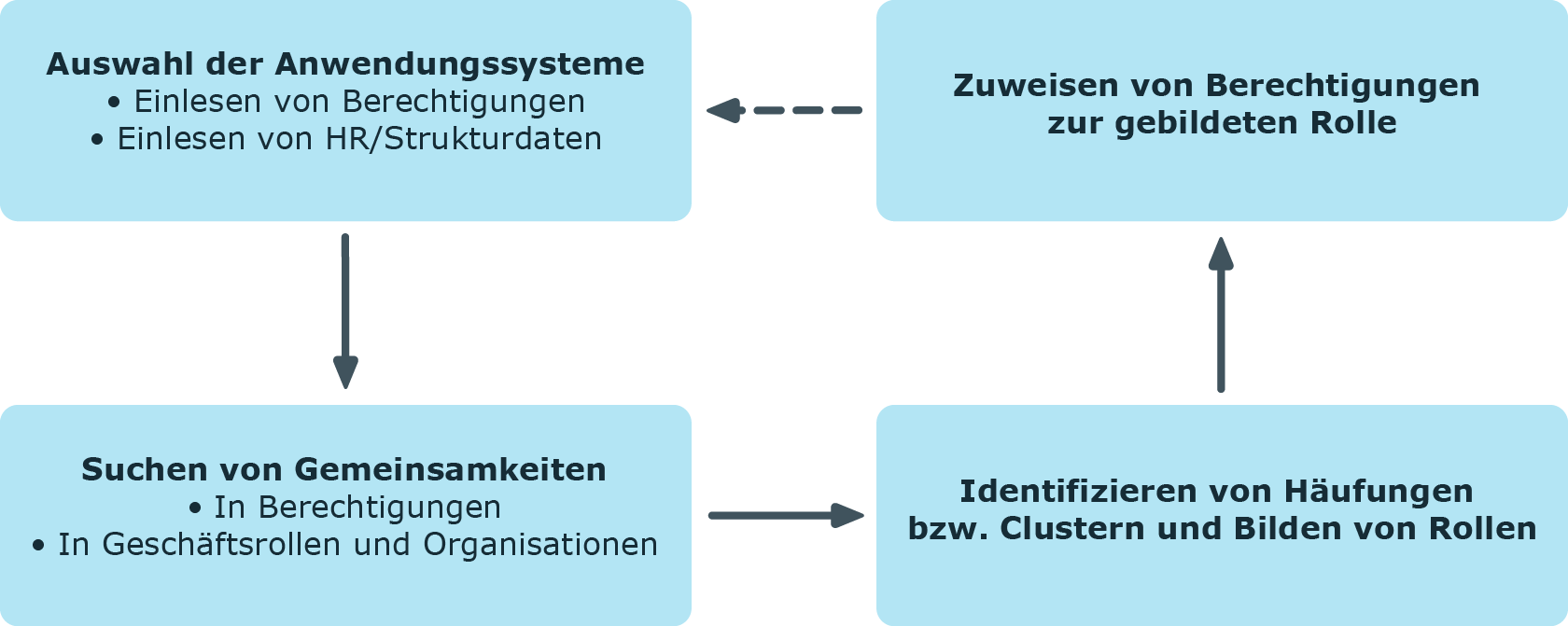
Bei den Clusteringverfahren berechnet der Analyzer aus Berechtigungen eines Benutzers in den verschiedenen Anwendungssystemen, wie Active Directory, HCL Domino oder SAP R/3, eine Häufigkeitsverteilung. Dabei kann einzelnen Berechtigungen im Vergleich zu anderen eine höhere Wichtigkeit eingeräumt werden. So kann beispielsweise die Anzahl der Mitglieder einer Berechtigung ein solches Kriterium darstellen. Dies wird durch den Analyzer bei der Berechnung erkannt und durch Gewichtung bei der Abstandsbetrachtung zwischen den einzelnen Clustern berücksichtigt. So können die bei der Analyse entstehenden hierarchische Strukturen bereits im Vorfeld optimiert und eine möglichst kleine Anzahl von Rollen erzielt werden.