
Using Match Strength to Reduce the Number of Rules
A simple rule uses logic to determine if there is a match, and a match strength to be used to determine categorization. You can build more complex rules with variations of the logic, resulting in different match strengths. For example, a rule that locates identity numbers such as Social Security numbers could be written so that:
- If there are 10 instances, the match strength is 1.0
- If there are 5 instances, the match strength is 0.5
- If there is 1 instance, the match strength is 0.25
In this case, it is important to consider how <if> blocks are processed. Once a match is found, no more conditions are processed. The condition with the strongest match strength should be the first <if> block, followed by subsequent match strengths in decreasing order.
The rule XML might look like this:
<if>
<find id=”Extractors.National.Identity.All”mincount=”10”/>
<match strengrh=”1”/>
</if>
<if>
<find id=”Extractors.National.Identity.All”mincount=”5”/>
<match strengrh=”0.5”/>
</if>
<if>
<find id=”Extractors.National.Identity.All”mincount=”2”/>
<match strengrh=”0.25”/>
</if>
Working with Text Extractors
Contents
- Identifying Text Extractors used within the System
- Creating Text Extractors
- Validating the Text Extractor
- Editing Text Extractors
- Removing Text Extractors
- Working with Regular Expression Text Extractors
- Working with Dictionary Text Extractors
- Managing Public Dictionary Text Extractors
- Managing Protected Dictionary Text Extractors
- Managing Dictionary Text Extractors with PowerShell
- Working with Advanced Text Extractors
Categorization starts by comparing the text in a resource to a defined list of match criteria. This defined list is known as a text extractor. You can build rules using text extractors. For example, if you want to locate credit card numbers, you may need to look for the following:
- Numbers that have 13 to 16 digits
- The number may have a space after every fourth digit
- The number may have a dash after every fourth digit
- The number may have no spaces or dashes
A text extractor is where the requirements for a “credit card number” are defined. You can use multiple text extractors together in a single rule. Using the above example, there can be numerical sequences that match your text extractor that are not actually credit cards. To increase the accuracy of credit card identification, you could use a second text extractor that looks for credit card providers such as Visa, MasterCard or American Express. Text extractors are built separately, and then referenced in rules. This allows you to reuse your text extractors.
The text extractors are used in a rule, which, when applied to a resource may result in a match.
The following diagram shows the building blocks of a taxonomy, and how you can reuse text extractors, grammars, entities, and pattern matches:
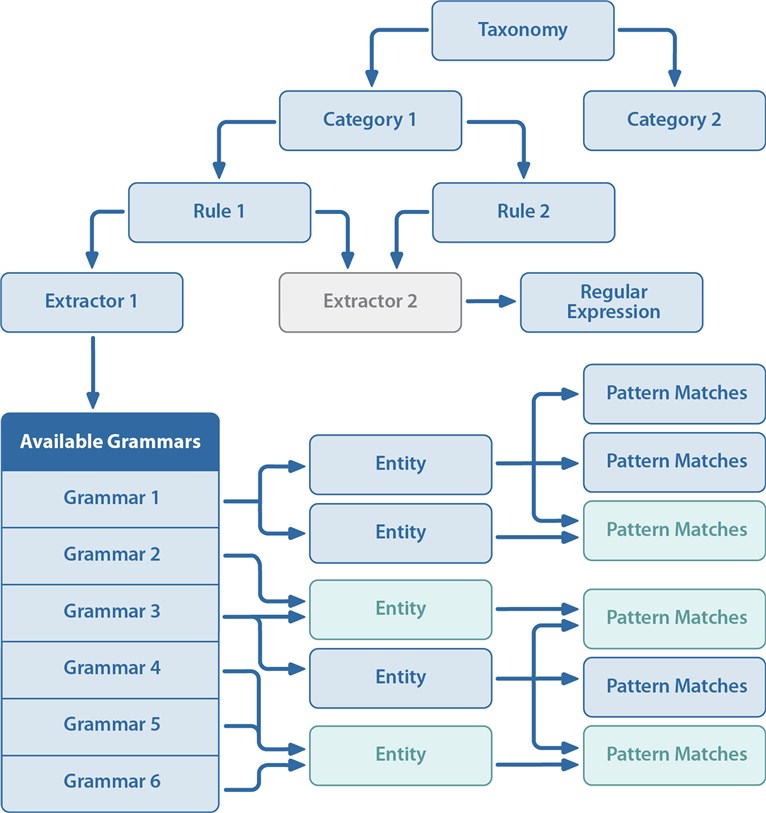 |
A good starting point for understanding text extractors is to view the text extractors included in Quest One Identity Manager Data Governance Edition. You will be able to see a variety of implementations of the xml through the Categorization Manager.
You can work with text extractors using the following methods:
- Web Portal, under the Governed Data node
- Powershell snap-in (see Adding the PowerShell Snap-ins)
For details on the various types of available text extractors see:
Identifying Text Extractors used within the System
Through the web portal, you can quickly view the text extractors that are included in the system and available for use within rules. At a glance you can see the text extractor ID, name, description, type, and associated rules.
| Before you can remove a text extractor from the system, you must remove any associations to rules. You can see which rules are associated with each text extractor and remove them through the web portal or through PowerShell. |
To view a list of text extractors in the classification system using the web portal
- Select Governed Data | Categorization Manager | Extractors.
You will be able to see extractor information including its name, description, and type. - From here, you can create, edit, or delete your text extractors.
To view a list of rules that have been associated with a given text extractor
- Select Governed Data | Categorization Manager | Extractors.
- Select a text extractor, click Edit, and choose the Associated Rules tab.
To view a list of all text extractors with PowerShell
- Run the Get-QTextExtractors command with the following parameter:
-
- ServerAddress
Provide the name of the computer hosting the Data Governance server, and the port. Enter in the form computername:port number. The default port is 8723.
- ServerAddress
To view a regular expression text extractor with PowerShell
- Run the Get-QRegexTextExtractor command with the following parameters:
-
- ServerAddress
Provide the name of the computer hosting the Data Governance server, and the port. Enter in the form computername:port number. The default port is 8723. - Id
Provide the id for the text extractor. You can get this by running the Get-QTextExtractors command.
- ServerAddress
To view a dictionary text extractor with PowerShell
- Run the Get-QDictionaryTextExtractor command with the following parameters:
-
- ServerAddress
Provide the name of the computer hosting the Data Governance server, and the port. Enter in the form computername:port number. The default port is 8723. - Id
Provide the id for the text extractor. You can get this by running the Get-QTextExtractors command.
- ServerAddress
To view an advanced text extractor with PowerShell
- Run the Get-QAdvancedTextExtractor command with the following parameters:
-
- ServerAddress
Provide the name of the computer hosting the Data Governance server, and the port. Enter in the form computername:port number. The default port is 8723. - Id
Provide the id for the text extractor. You can get this by running the Get-QTextExtractors command.
- ServerAddress
To view the text extractors used in a specific taxonomy with PowerShell
- Determine the taxonomy ID.
See Finding a Taxonomy, Category, or Extractor ID using PowerShell for details. - Run the Export-QTaxonomy command with the following parameters:
- ServerAddress
Provide the name of the computer hosting the Data Governance server, and the port. Enter in the form computername:port number. The default port is 8723. - TaxonomyId
- IncludeEntityExtractors
Set this to $true to include the text extractors in the export. - OutputFile
Provide the path to a file to store the template XML.
The taxonomy will be output to the screen if you omit this parameter.
- ServerAddress
To view the list of rules that have been associated with a given text extractor with PowerShell
- Make sure you know the text extractor ID.
You can use the Get-QTextExtractors command for a full listing of all text extractors in the system. - Run the Get-QRulesAssociatedWithTextExtractor command with the following parameters:
- ServerAddress
Provide the name of the computer hosting the Data Governance server, and the port. Enter in the form computername:port number. The default port is 8723. - ExtractorId.
You will be able to see all associated rule information including its name, description, id, and whether or not it is enabled within the system.
- ServerAddress
Creating Text Extractors
Creating new text extractors for the classification system is a multi-level process that allows you to refine the match criteria at each step.
When creating a text extractor:
- Begin by selecting the type of extractor to create (Regular Expression, Dictionary, or Advanced).
- Next, provide a meaningful and descriptive name and ID as the text extractor can be shared across many rules and categories.
- Then refine your text extractor to meet your exact needs through patterns and matches.
- Test the validity to ensure that it is properly formatted for the classification system.
If you are introducing a new text extractor to your environment and want to test it before using it in your production environment, you can create an unpublished test category or taxonomy, create a rule referencing the new text extractor and associate it with the category. Once you have associated it with a category, you can test it using the Get-QAllRuleResults command to view the results of all rules in the system when run against a test file.
For specific details see: