The following procedure illustrates the route of a log message from its source on the syslog-ng client to its final destination on the central syslog-ng server.
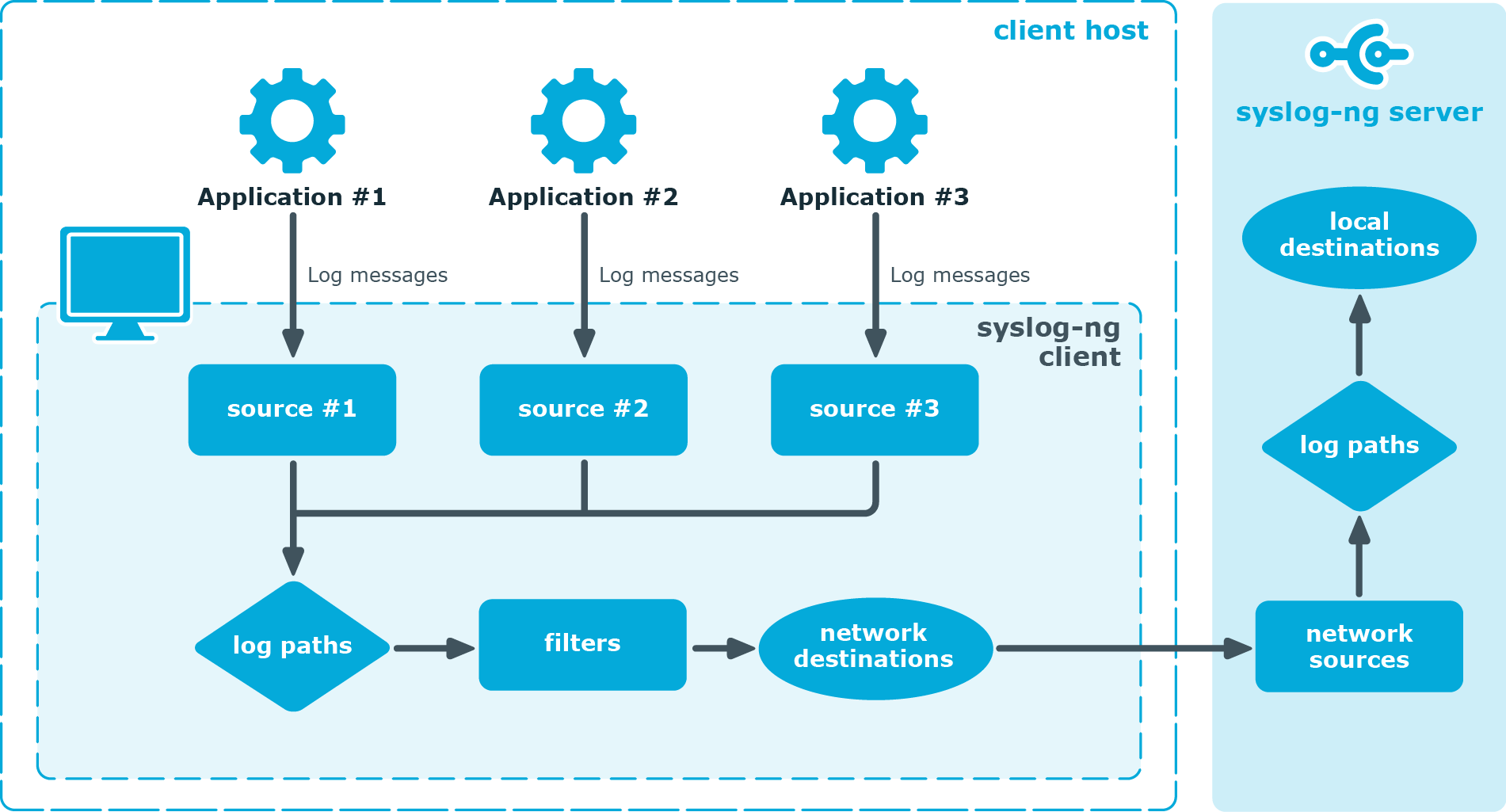
Figure 1: The route of a log message
-
A device or application sends a log message to a source on the syslog-ng client. For example, an Apache web server running on Linux enters a message into the /var/log/apache file.
-
The syslog-ng client running on the web server reads the message from its /var/log/apache source.
-
The syslog-ng client processes the first log statement that includes the /var/log/apache source.
-
The syslog-ng client performs optional operations (message filtering, parsing, and rewriting) on the message, for example, it compares the message to the filters of the log statement (if any). If the message complies with all filter rules, syslog-ng sends the message to the destinations set in the log statement, for example, to the remote syslog-ng server.
|

|
Caution:
Message filtering, parsing, and rewriting is performed in the order that the operations appear in the log statement. |
NOTE: The syslog-ng client sends a message to all matching destinations by default. As a result, a message may be sent to a destination more than once, if the destination is used in multiple log statements. To prevent such situations, use the final flag in the destination statements. For details, see Log statement flags.
-
The syslog-ng client processes the next log statement that includes the /var/log/apache source, repeating Steps 3-4.
-
The message sent by the syslog-ng client arrives from a source set in the syslog-ng server.
-
The syslog-ng server reads the message from its source and processes the first log statement that includes that source.
-
The syslog-ng server performs optional operations (message filtering, parsing, and rewriting) on the message, for example, it compares the message to the filters of the log statement (if any). If the message complies with all filter rules, syslog-ng sends the message to the destinations set in the log statement.
|
|
Caution:
Message filtering, parsing, and rewriting is performed in the order that the operations appear in the log statement. |
-
The syslog-ng server processes the next log statement, repeating Steps 7-9.
The syslog-ng Premium Edition application has three distinct typical operation scenarios: Client, Server, and Relay. The syslog-ng PE application running on a host determines the mode of operation automatically based on the license and the configuration file.
Figure 2: Client-mode operation
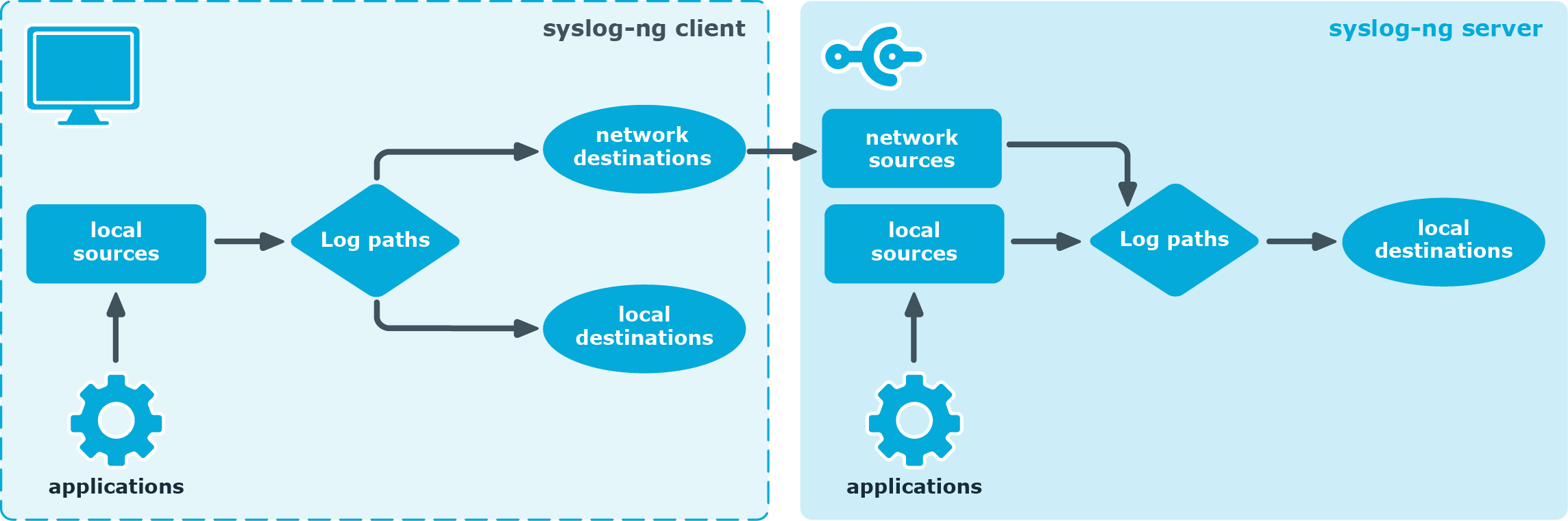
In client mode, syslog-ng collects the local logs generated by the host and forwards them through a network connection to the central syslog-ng server or to a relay. Clients often also log the messages locally into files.
No license file is required to run syslog-ng in client mode.
Figure 3: Relay-mode operation
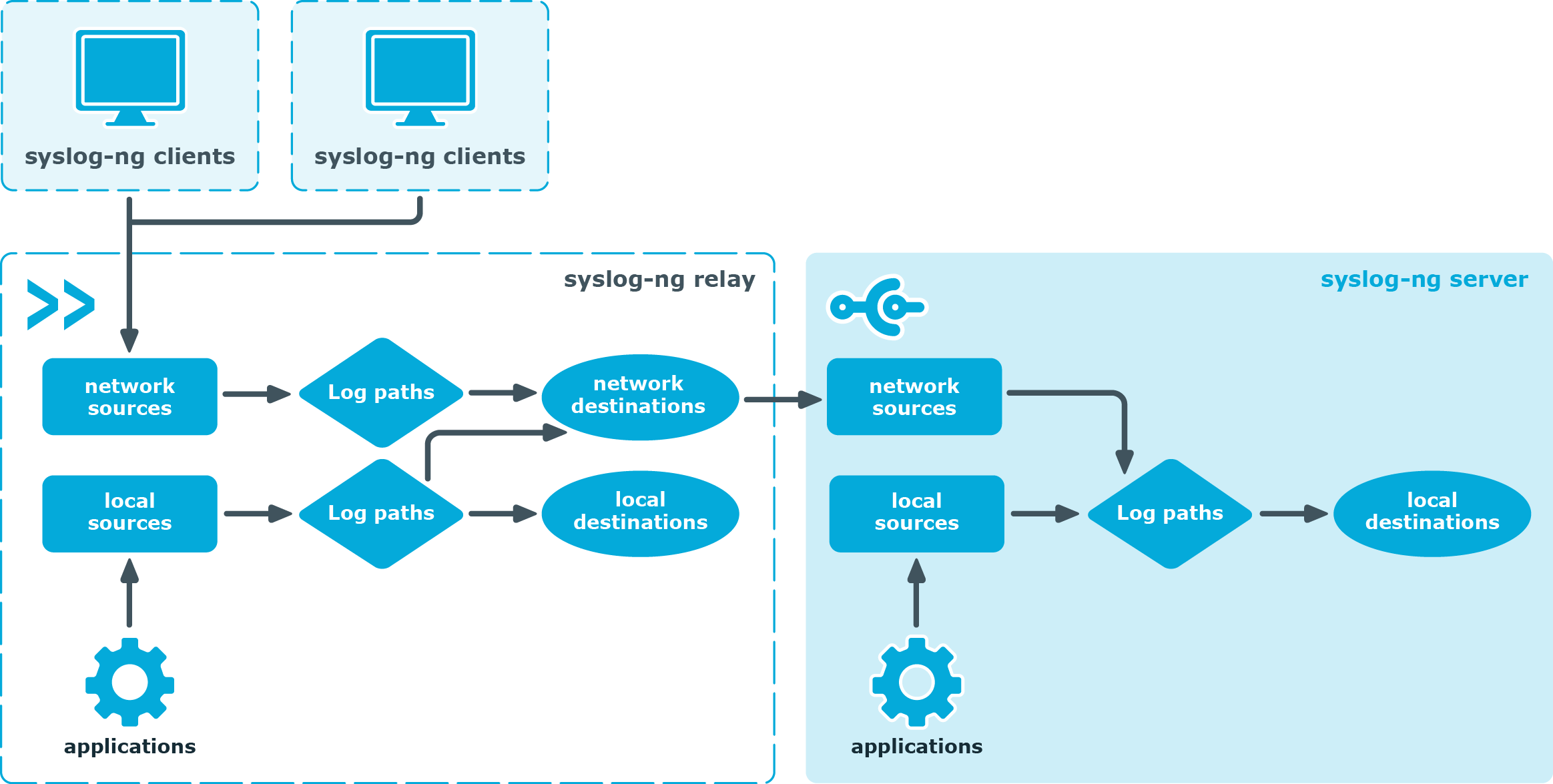
In relay mode, syslog-ng receives logs through the network from syslog-ng clients and forwards them to the central syslog-ng server using a network connection. Relays also log the messages from the relay host into a local file, or forward these messages to the central syslog-ng server.
You cannot use the following destinations in relay mode: elasticsearch2(), hdfs(), kafka(), mongodb(), pipe(), smtp(), sql() and stackdriver(). The file() and logstore() destinations work only for local messages that are generated on the relay.
No license file is required to run syslog-ng in relay mode.
Example relay use cases
The relay collects log messages through the network and after processing, but without writing them on the disk for storage, forwards them to one or more remote destinations.
You can use a relay for many different use cases as described in the examples below.
UDP-only source devices
Most network devices send log messages over UDP. However, UDP does not guarantee that all packets are delivered, which makes UDP unreliable.
To ensure at least a best effort level of reliability, One Identity recommends that you deploy a relay on the network, close to the source devices. With the most reliable hops between the source and the relay, you can minimize the risk of losing UDP packets. Once the packet arrives at the relay, syslog-ng OSEsyslog-ng PE ensures that the messages are delivered to the central server in a reliable manner, based on TCP/TLS and Advanced Log Transfer Protocol (ALTP).
Too many source devices
Depending on the hardware and configuration, an average syslog-ng instance can usually handle the following number of concurrent connections:
If you have more source devices, you must deploy a relay machine at least per 5,000 sources and batch up all the logs into a single TCP connection that connects the relay to the server. If TLS or ALTP is used, deploy relays per 1,000 source devices.
Collecting logs from remote sites (especially over public WAN)
If you need to collect log messages from geographically remote sites or over public WAN, One Identity recommends that you install at least a relay node per each remote site. The relay can be the last outgoing hop for all the messages of the remote site, which has several benefits:
-
Maintenance: You only need to change the configuration of the relay if you want to re-route the logs of some or all sources of the remote site. Also you do not need to change each source’s configuration one by one.
-
Security: If you trust your internal network, it is not necessary to hold encrypted connections within the LAN of the remote site as the messages can get to the relay without encryption. Messages must be sent in an encrypted way over the public WAN, and it is enough to hold only a single TCP/TLS connection between the sites, that is, between the remote relay and the central server. This eliminates the wasting of resources as holding several TLS connections directly from the clients is more costly than holding a single connection from the relay.
-
Reliability: You can set up a main disk-buffer on the relay. The main disk-buffer is only responsible for buffering all the logs of the remote site if the central syslog-ng OSEsyslog-ng PE server is temporarily unavailable. It is easier to maintain this single main disk-buffer instead of setting disk-buffers on individual client machines.
Separation, distribution, and balancing of message processing tasks
Most Linux applications have their own human readable, but difficult to handle, log messages. Without parsing and normalization it is difficult to alert and report on these log messages. Many syslog-ng users use the message parsing tools of syslog-ng to normalize their different log messages. Just like normalization, filtering can also be resource-heavy, depending on what the filtering is based on. In this case, it might be inefficient to perform all the message processing tasks on the server as it can result in decreased overall performance.
It is a typical setup to deploy relays in front of the central server operating as a receiver front-end. Most resource-heavy tasks, for example, parsing, filtering, and so on, are performed on this receiver layer. As all resource-heavy tasks are performed on the relay, the central server behind it only needs to get the messages from the relay and write them into the final text-based or tamper-proof (logstore) format. Since you can run several relays, you can balance the resource-heavy tasks between more relays, and a single server behind the relays can still be fast enough to write all the messages on the disk.
Acting as a relay also depends on the functionality. A relay does not have to be a dedicated relay machine at all. For log collection, it can be one of the clients with a relay configuration. Note that in a robust log collection infrastructure, the relays have their own purpose, and One Identity recommends running dedicated relay machines.
You can run several parallel relays to ensure horizontal redundancy. For example, if each of the relays has the same configuration, when one relay goes down another relay can take over the processing. Distribution of the logs can be done by the built-in client-side failover functionality and also by a general load balancer. The load balancer is also used to serve N+1 redundant relay deployments. In this case, switching from one relay to another relay is done when there is an outage but also for real load balancing purposes.
What syslog-ng relays are not good for
The purpose of the relay is to buffer the logs for short term, for example, a few minutes or a few hours long outages (depending on the log volume). It is not designed to buffer logs generated by the sources during a very long server or connection outage, for example, up to a few days long.
If you expect extended outages, One Identity recommends that you deploy servers instead of relays. There are many deployments where long term storage and archiving are performed on the central syslog-ng server, but relays also do short-term log storage. From the syslog-ng PE point of view, these are servers, and thus need separate server licenses.
