
How it works
NOTE: The example presented here is set in a client-relay-server scenario.
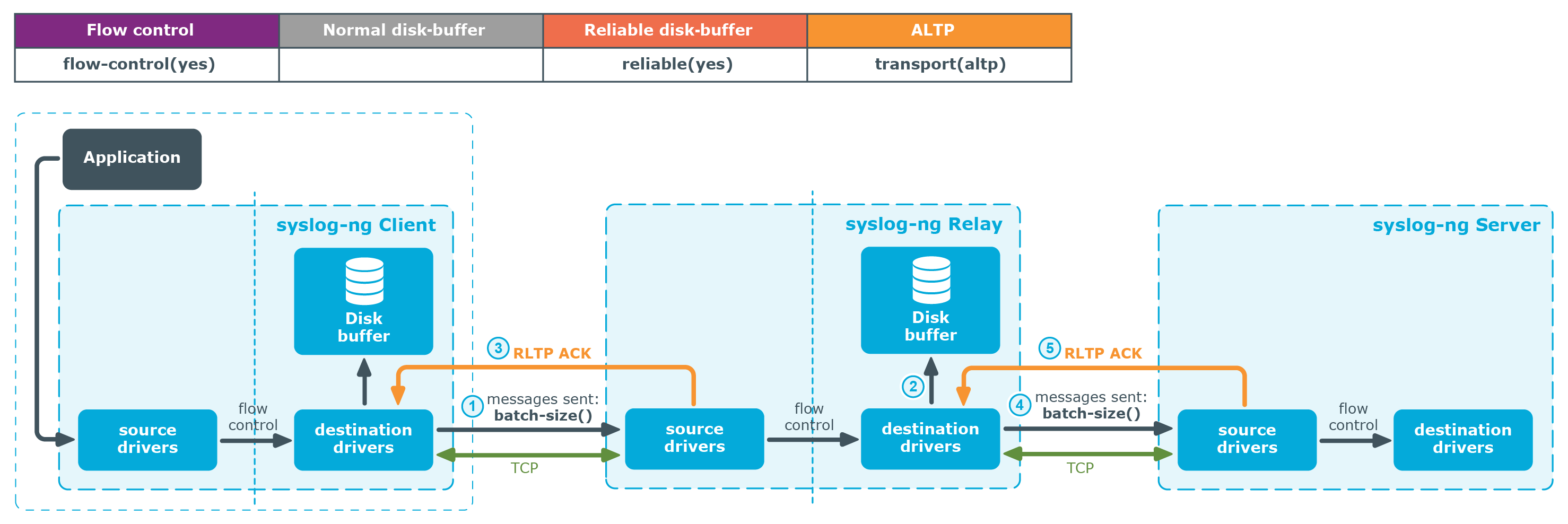
- The sender sends messages in batches (set via batch-size()).
- The relay writes messages to the disk-buffer file.
-
Once messages have been written to the disk-buffer file, the relay returns an acknowledgment to the client.
- The relay sends messages to the server in batches (set via batch-size()).
-
When the server has successfully received and processed the messages in the batch, it sends an acknowledgment of the processed messages to the relay.
It is only at this point that the relay removes log messages from the disk-buffer file because this is when logs are considered "delivered" to the server.
After receiving the acknowledgment, the sender sends another batch of messages.
This configuration gives you the greatest degree of protection against log message loss. ALTP provides acknowledgment about the successful processing of log messages at the level of the application layer. Even if the reception of log messages has been acknowledged by TCP at the transport layer, log messages are considered delivered only when the syslog-ng PE application has received an acknowledgment from the other syslog-ng PE instance about the successful delivery of log messages.
This mechanism guarantees that log messages are not lost between the client and the relay, or between the relay and the server, or on the relay itself. To minimize the risk of message loss on the client or the server, use flow control and reliable disk-buffer.
Figure 41: Flow control, reliable disk-buffer, ALTP
How to set key parameters
Set flags(flow-control) in the log path.
Configure the disk-buffer option. For details, see Example: Example configuration of the reliable disk-buffer.
Example: Example configuration of the reliable disk-buffer
disk-buffer( mem-buf-size(10485760) # storing 10 MB messages in memory and on disk disk-buf-size(2147483648) # storing 2 GB of messages only on disk reliable(yes) )
Enable ALTP by setting transport(rltp). For details, see ALTP options.
Benefits
This configuration minimizes the loss of log messages in the following situations:
- Unreachable destination server(s): Only as many incoming log messages are read as can be "delivered". When flow control is used in combination with reliable disk buffering and ALTP, those messages are considered delivered by the very first source driver that have been written to the disk buffer. syslog-ng PE will not read new messages until the previous batch has been written to the disk buffer.
- TCP error: With a TCP connection, when messages are sent from the destination drivers to the destination servers, messages are written to the TCP socket. The TCP socket sends an acknowledgment to the destination drivers once it has successfully processed messages. However, while the acknowledge messages sent by the TCP socket implement flow control at the transport layer, ALTP introduces flow control at the application layer. This means that log messages are only considered delivered when the ALTP acknowledge message is returned at the level of the syslog-ng application. That is to say, when a TCP error occurs, messages that have been written to the disk-buffer file do not get lost.
- Message loss outside of syslog-ng PE: One of the advantages of this configuration over when the disk-buffer option is not used at all is that when the log-iw-size() control window is full, the flow-control mechanism stops reading logs from the sources much later. This is because when it is not possible to send logs directly to the destinations, they are written to the disk. It is only after the disk-buffer file has been filled to its full capacity that the sources are stopped. This allows you to minimize the loss of log messages during peak hours or when the network is temporarily down.
-
Message loss when syslog-ng PE is stopped or restarted: When syslog-ng is stopped or restarted, the contents of the disk-buffer file do not get lost, greatly increasing reliability.
Also note that the memory buffer is only used as a cache in this configuration. Any data stored in the memory has already been written to the disk-buffer file, which, again, results in more reliability.
NOTE: In rare cases, the buffers stored on the disk can become corrupted, in which case syslog-ng PE may not able to process all the logs stored in the disk-buffer file.
- When syslog-ng PE is not able to operate normally (for example, when syslog-ng PE crashes due to some unforeseen event): No messages get lost because the disk-buffer option is persistent and when the disk-buffer file is full, syslog-ng PE stops reading messages from the sources. When syslog-ng PE is restarted after a crash, it automatically recovers any unsent messages from the disk-buffer file and the output buffer. After the restart, syslog-ng PE sends the saved messages to the destination.
Drawbacks
This configuration results in the slowest processing time out of all the options described in this chapter.