Um Vererbungsberechnungen als Folge einer Änderung am System zu verfolgen, wird die GenProcID in den Operationen des DBQueue Prozessor mitgeführt. Für eventuelle Folgeoperationen muss sichergestellt sein, dass es je Operation und Objekt nur einen Eintrag in der DBQueue gibt. Um derartige Prozesse abzubilden, wird für diese eine neue GenProcID vergeben und in weiteren Prozessen verwendet. Die kollidierten Prozesse und ihre GenProcID’s werden in der Tabelle DialogProcessSubstitute abgebildet.
Bei der Erzeugung neuer GenProcID für kollidierte Prozesse gelten folgende Regeln:
-
Mehrere gleiche Operationen des DBQueue Prozessor auf einem Objekt werden zu einem Prozess (einer GenProcID) zusammengeführt. Dabei werden vorhandene Ersatzprozesse genutzt, wenn die Menge ihrer Vorgänger, bezogen auf Basisprozesse, identisch ist.
-
Sollte es in der Folge zu weiteren Kollisionen kommen, so werden schon ersetzte GenProcID zuerst in ihre Ursprünge aufgelöst und dann ein neuer Ersatz gebildet.
-
Ein Ersatz gilt genau für eine Menge an Ursprungsprozessen.
Der Konfigurationsparameter QBM | DBQueue | GenProcIDReplaceLimit definiert den Grenzwert für Prozessersetzungen. Diese Maximalzahl von kollidierenden Prozessen wird in der Tabelle DialogProcessSubstitute abgebildet. Bei Bedarf können Sie den Konfigurationsparameter im Designer aktivieren und den Wert anpassen.
Verwandte Themen
Es existiert eine hierarchische Rollenstruktur bestehend aus 4 Rollen O1, O2, O3 und O4. Die Person X ist den Rollen O1, O4 und O3 zugeordnet. Nachfolgend wird die Zuweisung von Software an die Rollen betrachtet.
Abbildung 30: Abbildung der Rollenstruktur laut Beispiel
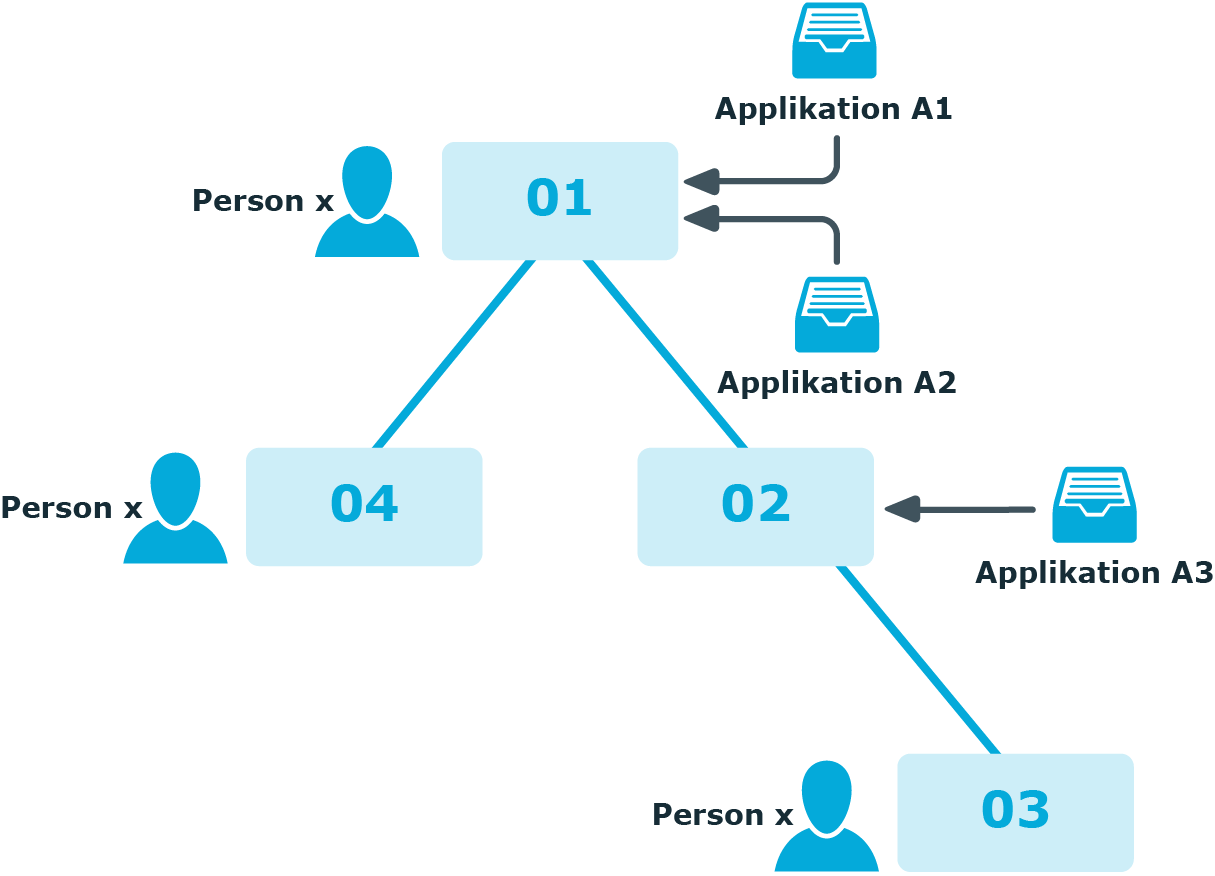
Zwischen zwei Ausführungen des DBQueue Prozessor laufen drei Prozesse mit jeweils eigener GenProcID an der Oberfläche ab:
-
P1: Zuweisung Software A1 an die Rolle O1
-
P2: Zuweisung Software A2 an die Rolle O1
-
P3: Zuweisung Software A3 an die Rolle O2
Im Ergebnis stehen folgende Operationen in der DBQueue (Tabelle DialogDBQueue) und der Prozessinformation:
|
OrgHasApp |
O1 |
P1 |
|
OrgHasApp |
O1 |
P2 |
|
OrgHasApp |
O2 |
P3 |
Die Operation OrgHasApp bezüglich O1 kann nicht aufgeteilt werden, da für O1 die Vereinigungsmenge der Software errechnet wird. Zu diesem Zeitpunkt ist auch keine Information mehr verfügbar, welche GenProcID durch die Zuordnung welcher Software eingetragen wurde.
Um Eindeutigkeit bezüglich der Kombination Operation und Objekt zu erreichen, wird eine neue GenProcID P4 eingeführt und die beiden Operationen bezüglich O1 auf diese verdichtet. In der Tabelle DialogProcessSubstitute wird vermerkt, dass P4 die möglichen (aber in der Einzelaktion nicht eindeutigen) Vorgänger P1 und P2 hat.
|
OrgHasApp |
O1 |
P4 |
|
OrgHasApp |
O2 |
P3 |
Abhängig, ob OrgHasApp eine Operation ist, die im Einzelschritt- oder im Bulkverfahren abgearbeitet wird, kann es jetzt zu folgenden Konstellationen kommen:
- Fall 1) Die Berechnung für O1 wird ausgeführt, dann die Operation für O2.
- Fall 2) Die Berechnung für O2 wird ausgeführt, dann die Operation für O1.
- Fall 3) Die Berechnungen für O1 und O2 werden in einer Bulkoperation gleichzeitig ausgeführt.
Nach Ausführung dieser Operationen und unter der Annahme, dass sie alle zu Änderungen an den betroffenen totalen Mengen führen, ergeben sich folgende Zustände:
Fall 1) Die Berechnung für O1 wird ausgeführt, dann die Operation für O2.
|
OrgHasApp |
O2 |
P3 |
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O2 |
P4 |
|
OrgHasApp |
O3 |
P4 |
|
PersonHasApp |
X |
P4 |
Vor dem nächsten Lauf des DBQueue Prozessors muss wieder eine Verdichtung der GenProcID’s vorgenommen werden, da für die Operation OrgHasApp für Objekt O2 keine Eindeutigkeit gegeben ist. P5 wird eingeführt, mit den möglichen Vorgängern P4 und P3.
|
OrgHasApp |
O2 |
P5 |
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O3 |
P4 |
|
PersonHasApp |
X |
P4 |
Jetzt wird die Berechnung für O2 ausgeführt:
|
OrgHasApp |
O3 |
P5 |
|
PersonHasApp |
X |
P5 |
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O3 |
P4 |
|
PersonHasApp |
X |
P4 |
Da für O3 keine Eindeutigkeit gegeben ist, wird P6 eingeführt mit den möglichen Vorgängern P4 und P5.
|
OrgHasApp |
O3 |
P6 |
|
PersonHasApp |
X |
P5 |
|
OrgHasApp |
O4 |
P4 |
|
PersonHasApp |
X |
P4 |
Nach den Berechnungen für O3 und O4 liegt folgende Situation vor:
|
PersonHasApp |
X |
P6 |
|
PersonHasApp |
X |
P5 |
|
PersonHasApp |
X |
P4 |
Für das Objekt X ist keine Eindeutigkeit gegeben, so dass P7 mit den möglichen Vorgängern P4, P5 und P6 eingeführt wird.
Fall 2) Die Berechnung für O2 wird ausgeführt, dann die Operation für O1.
|
OrgHasApp |
O1 |
P4 |
|
OrgHasApp |
O2 |
P3 |
Nach der Ausführung stehen folgende Einträge in der DBQueue:
|
OrgHasApp |
O1 |
P4 |
|
OrgHasApp |
O3 |
P3 |
Nach dem nächsten Ausführungsschritt liegt folgende Situation vor:
|
OrgHasApp |
O3 |
P3 |
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O2 |
P4 |
|
OrgHasApp |
O3 |
P4 |
|
PersonHasApp |
X |
P4 |
Für die Eindeutigkeit von O3 muss ein Prozess P5 mit den möglichen Vorgängern P3 und P4 erzeugt werden:
|
OrgHasApp |
O3 |
P5 |
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O2 |
P4 |
|
PersonHasApp |
X |
P4 |
Nach den Berechnungen liegt folgende Situation vor:
|
PersonHasApp |
X |
P5 |
|
PersonHasApp |
X |
P4 |
Für das Objekt X ist keine Eindeutigkeit gegeben, so dass P6 mit den möglichen Vorgängern P4 und P5 eingeführt wird.
Fall 3) Die Berechnungen für O1 und O2 werden in einer Bulkoperation gleichzeitig ausgeführt.
|
OrgHasApp |
O1 |
P4 |
|
OrgHasApp |
O2 |
P3 |
Nach dem ersten Berechnungsschritt stehen folgende Informationen in der DBQueue:
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O2 |
P4 |
|
OrgHasApp |
O3 |
P4 |
|
OrgHasApp |
O3 |
P3 |
|
PersonHasApp |
X |
P4 |
Für O3 wird durch Prozess P5 mit den möglichen Vorgängern P3 und P4 Eindeutigkeit hergestellt:
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O2 |
P4 |
|
OrgHasApp |
O3 |
P5 |
|
PersonHasApp |
X |
P4 |
Nach dem nächsten Berechnungsschritt ist folgender Inhalt zu finden:
|
OrgHasApp |
O3 |
P4 |
|
PersonHasApp |
X |
P4 |
|
PersonHasApp |
X |
P5 |
Nachdem im nächsten Durchlauf O3 errechnet wurde und dieser keinen neuen PersonHasApp-Eintrag erzeugt hat, da X mit P4 schon existiert, steht zum Schluss nur X mit P4 und P5.
|
PersonHasApp |
X |
P4 |
|
PersonHasApp |
X |
P5 |
Für das Objekt X ist keine Eindeutigkeit gegeben, so dass P6 mit den möglichen Vorgängern P4 und P5 eingeführt wird.
Alle im One Identity Manager protokollierten Aufzeichnungen werden zunächst in der One Identity Manager-Datenbank gespeichert. Der Anteil der historisierten Daten am Gesamtvolumen einer One Identity Manager-Datenbank sollte maximal 25 % betragen. Anderenfalls kann es zu Performance-Problemen kommen. Die Aufzeichnungen sollten in regelmäßigen Abständen aus der One Identity Manager-Datenbank entfernt und archiviert werden.
Um die aufgezeichneten Daten in regelmäßigen Abständen aus der One Identity Manager-Datenbank zu entfernen, werden folgende Verfahren angeboten:
-
Die Daten können direkt aus der One Identity Manager-Datenbank in eine One Identity Manager History Database übernommen werden. Dieses ist das Standardverfahren für die Datenarchivierung. Wählen Sie dieses Verfahren, wenn die Server auf denen die One Identity Manager-Datenbank und die One Identity Manager History Database liegen einander sehen.
-
Die Daten werden ohne Archivierung nach einer festgelegten Zeitspanne aus der One Identity Manager-Datenbank gelöscht.
Ausführliche Informationen zur Einrichtung der Archivierung von Daten in einer History Database finden Sie im One Identity Manager Administrationshandbuch für die Datenarchivierung.
Detaillierte Informationen zum Thema
Sollen die Aufzeichnungen einzelner Teilbereiche für einen gewissen Zeitraum in der One Identity Manager-Datenbank gehalten werden, jedoch keine spätere Archivierung erfolgen, dann haben Sie folgende Möglichkeiten:
-
Um einen einzelnen Teilbereich von der Archivierung auszuschließen, konfigurieren Sie diesen Teilbereich nicht für den Export, sondern legen nur den Aufbewahrungszeitraum fest.
-
Um alle Teilbereiche ohne Archivierung direkt zu löschen, legen Sie die Aufbewahrungszeiten fest. Aktivieren Sie im Designer den Konfigurationsparameter Common | ProcessState | ExportPolicy und tragen Sie den Wert NONE ein.
Die Aufzeichnungen werden nach Ablauf der Aufbewahrungszeit durch den DBQueue Prozessor aus der One Identity Manager-Datenbank gelöscht. Zusätzlich werden alle Einträge für ausgelöste Aktionen gelöscht, zu denen es keine Aufzeichnungen in den Teilbereichen gibt.
HINWEIS: Wenn Sie keine Aufbewahrungszeiten festlegen, werden die Aufzeichnungen dieser Teilbereiche innerhalb der täglichen Wartungsaufträge des DBQueue Prozessor aus der One Identity Manager-Datenbank gelöscht.
Verwandte Themen
