Daten zu Zieltabellen und Zielspalten zuordnen
Legen Sie im Data Import auf der Seite Zuordnung von Zieltabelle und Zielspalten fest, wie die Daten in der One Identity Manager-Datenbank abgelegt werden.
Um Zieltabelle und Zielspalten zuzuordnen
-
Im Bereich Zieltabelle wählen Sie die Zieltabelle aus, in die die Daten importiert werden.
TIPP: Über die Schaltfläche  im Bereich Zieltabelle ordnen Sie die Zielspalten und Schlüssel automatisch zu. Diesen Vorschlag sollten Sie immer prüfen.
im Bereich Zieltabelle ordnen Sie die Zielspalten und Schlüssel automatisch zu. Diesen Vorschlag sollten Sie immer prüfen.
Eine Spalte wird zugeordnet, wenn in der Zieltabelle eine Spalte gefunden wird, deren Bezeichnung mit der Bezeichnung der Quellspalte übereinstimmt.
-
Im Bereich Zielspalten und Schlüssel legen Sie die Abbildung der Daten in den Zielspalten der Tabelle fest.
HINWEIS: Ist noch keine Zielspalte zugeordnet, wird als Spaltenbezeichnung nicht zugeordnet angezeigt.
Klicken Sie neben einer Spaltenbezeichnung auf die Pfeilschaltfläche um den Zuordnungsassistenten zu öffnen und erfassen Sie für jede Spalte die folgenden Informationen.
Tabelle 45: Eigenschaften für Zielspalten und Schlüssel
|
Als Schlüsselspalte verwenden |
Gibt an, ob die Spalte als Schlüsselspalte verwendet wird.
Es können eine oder mehrere Schlüsselspalten definiert sein. Anhand der Schlüsselspalten werden die Datensätze ermittelt, die in die Datenbank zu importieren sind. Aus den Schlüsselspalten sollten sich die Datensätze eindeutig ermitteln lassen. |
|
Konvertierungsskript |
Mit dem Konvertierungsskript passen Sie die Werte der Quellspalte an die zulässigen Werte der Zielspalte an. Dies ist beispielsweise erforderlich, wenn für die Zielspalte eine Liste zulässiger Werte definiert ist.
Das Konvertierungsskript formulieren Sie in VB.Net-Syntax. Der Zugriff auf die Werte erfolgt über die Variable Value. Der Zugriff auf die Quellspalten erfolgt in $-Notation. Ausführliche Informationen zu Skripten im One Identity Manager finden Sie im One Identity Manager Konfigurationshandbuch. |
|
Zielspalte |
Wählen Sie die Zielspalte, in die die Daten importiert werden. Angezeigt werden die Spalten der Zieltabelle mit ihrem Datentyp. Dabei gilt:
-
Pflichtangaben, werden mit einem blauen Pfeil vor dem Datentyp gekennzeichnet.
-
Spalten ohne ausreichende Berechtigungen werden grau dargestellt.
-
Spalten, die per Präprozessorbedingung deaktiviert sind, werden nicht angezeigt.
TIPP:
-
Über die Schaltfläche wird eine Spalte vorgeschlagen, wenn in der Zieltabelle eine Spalte gefunden wird, deren Bezeichnung mit der Bezeichnung der Quellspalte übereinstimmt. Diesen Vorschlag sollten Sie immer prüfen.
-
Über die Option Beschriftung anzeigen wechseln Sie zwischen Anzeigename und technischem Namen der Spalte. |
TIPP: Im Zuordnungsassistenten können Sie über die Schaltfläche > zur nächsten Spalte wechseln. Im Bereich Datenvorschau sehen Sie eine Vorschau der Werte.
Verwandte Themen
Spalten mit festen Werten einfügen
Im Data Import können Sie zusätzliche Spalten mit festen Werten in den Datenimport einfügen und in eine definierte Spalte importieren.
Um Spalten mit festen Werten einzufügen
-
Klicken Sie im Bereich Zielspalten und Schlüssel neben einer beliebigen Spaltenbezeichnung auf die Pfeilschaltfläche um den Zuordnungsassistenten zu öffnen.
-
Klicken Sie die Schaltfläche  .
.
-
Geben Sie im Eingabefeld Fester Wert den gewünschten Wert ein.
- ODER -
Wenn der Wert aus den Werten von Quellspalten ermittelt werden soll, geben Sie ein Konvertierungsskript an.
-
Ordnen Sie die Zielspalte zu.
-
Schließen Sie den Zuordnungsassistenten.
Verwandte Themen
Hierarchie der Daten festlegen
Enthält ein Import Daten, die Abhängigkeiten untereinander besitzen, müssen Sie sicherstellen, das die Ziele der Verweise vor den Quellen der Verweise verarbeitet werden.
So können beispielsweise untergeordnete Abteilungen (Department.UID_Department) erst nach den übergeordneten Abteilungen (Department.UID_ParentDepartment) importiert werden.
HINWEIS:
-
Das Sortieren der Daten in eine hierarchische Struktur kann im Data Import sehr viel Speicher in Anspruch nehmen. Wenden Sie das hier genannte Vorgehen daher nur für Importe mit geringen Datenmengen an.
-
Für umfangreichere CSV-Importe, sortieren Sie die Daten bereits in der Importdatei entsprechend, um die Abhängigkeiten von Objekten aufzulösen.
-
Für umfangreiche Importe aus externen Datenbanken verwenden Sie die Order by-Klausel zur Sortierung der Daten.
Um im Data Import die Daten hierarchisch zu sortieren
-
Aktivieren Sie auf der Seite Hierarchie spezifizieren die Option Nach Hierarchie sortieren.
-
Wählen Sie die Schlüsselspalte in der die Daten abgebildet sind, beispielsweise Department.UID_Department.
-
Wählen Sie den Schlüssel des Elternelements, beispielsweise Department.UID_ParentDepartment.
Verwandte Themen
Optionen für die Mengenbehandlung
Legen Sie im Data Import auf der Seite Mengenbehandlungsoptionen fest, wie neue und bestehende Datensätzen beim Import behandelt werden. Der Import muss mehrere Fälle berücksichtigen und jeweils entsprechend reagieren. Während des Importes werden die Datensätze der Quelldaten mit den Einträgen der Datenbank verglichen. Über eine Bedingung können Sie die relevanten Datenbankeinträge weiter einschränken.
Über folgende Einstellungen legen Sie fest, wie die Datensätze verarbeitet werden.
Tabelle 46: Optionen für die Mengenbehandlung
|
Neue Sätze einfügen |
Der Datensatz aus den Quelldaten kommt noch nicht in der Datenbank vor. Ist die Option aktiviert, wird der Datensatz in die Datenbank eingefügt. |
|
Bestehende Sätze anpassen |
Es existiert ein Eintrag in der Datenbank, der dem Quelldatensatz entspricht. Ist die Option aktiviert, wird der Datensatz in der Datenbank aktualisiert.
Existieren mehrere Einträge in der Datenbank, die dem Quelldatensatz entsprechen, wird ein Eintrag ins Fehlerprotokoll geschrieben. |
|
Nicht mehr vorhandene Sätze löschen |
Es existiert ein Eintrag in der Datenbank, der nicht in den Quelldaten enthalten ist. Ist die Option aktiviert, wird der Eintrag aus der Datenbank gelöscht. |
|
Einschränkung der Zielobjekte |
Über eine Bedingung schränken Sie die Menge der relevanten Datenbankeinträge ein. Die Bedingung wird zu Beginn des Importes geprüft.
Für die Formulierung der Bedingung steht Ihnen über die Schaltfläche  neben dem Eingabefeld ein Assistent zur Verfügung. neben dem Eingabefeld ein Assistent zur Verfügung.
HINWEIS: Ist die Option Neue Sätze einfügen aktiviert, werden Quelldatensätze, die aufgrund der Einschränkung nicht im Bereich der relevanten Datenbankeinträge liegen, als neue Datensätze behandelt und in die Datenbank eingefügt. Dies kann unter Umständen zu Fehlerzuständen führen, beispielsweise doppelten Datensätzen. |
Beispiel für Mengenbehandlung
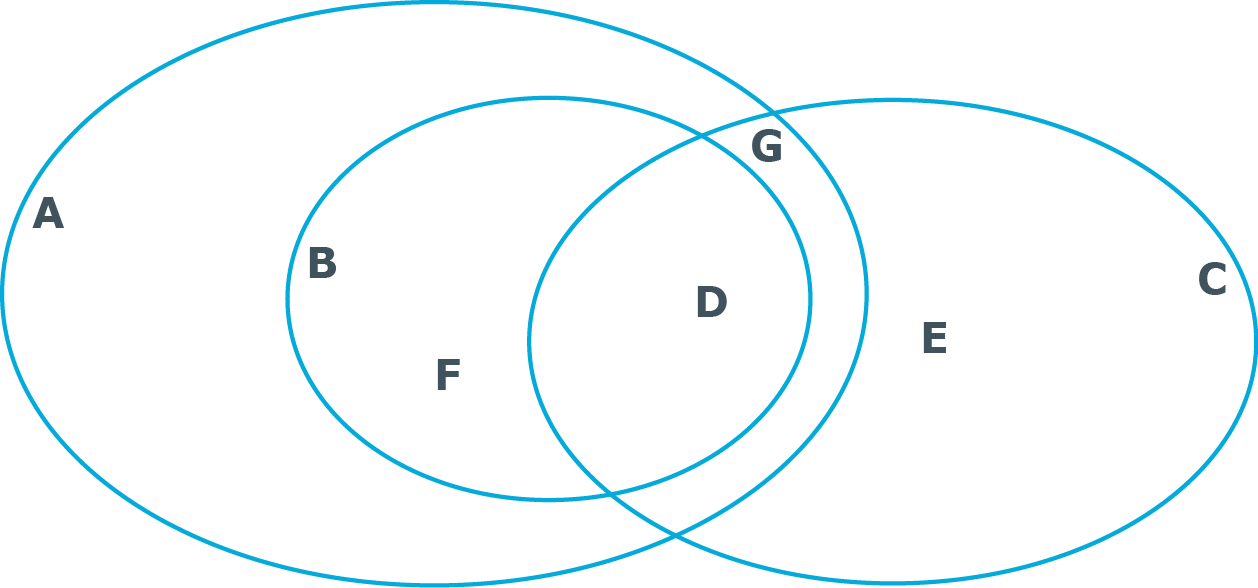
|
A |
Alle Objekte in der Datenbank. |
|
B |
Durch Bedingung eingeschränkte Menge der Datenbankeinträge. |
|
C |
Einträge in den Quelldaten. |
|
D |
Alle Einträge, die sowohl in der Datenbank als auch in den Quelldaten vorkommen. Typische Operation: Aktualisieren der Einträge in der Datenbank. |
|
E |
Einträge, die nur in den Quelldaten, nicht aber in der Datenbank vorkommen. Typische Operation: Einfügen neuer Einträge in die Datenbank. |
|
F |
Einträge, die in der Datenbank, nicht jedoch in den Quelldaten vorkommen. Typische Operation: Bereinigen der Einträge in der Datenbank. |
|
G |
Einträge, die in den Quelldaten vorkommen, nicht jedoch im ausgewählten Bereich der Datenbank liegen. Diese Einträge werden behandelt wie die Fall E, wobei ein Einfügen der Einträge unter Umständen zu Kollisionen führen kann. |
