
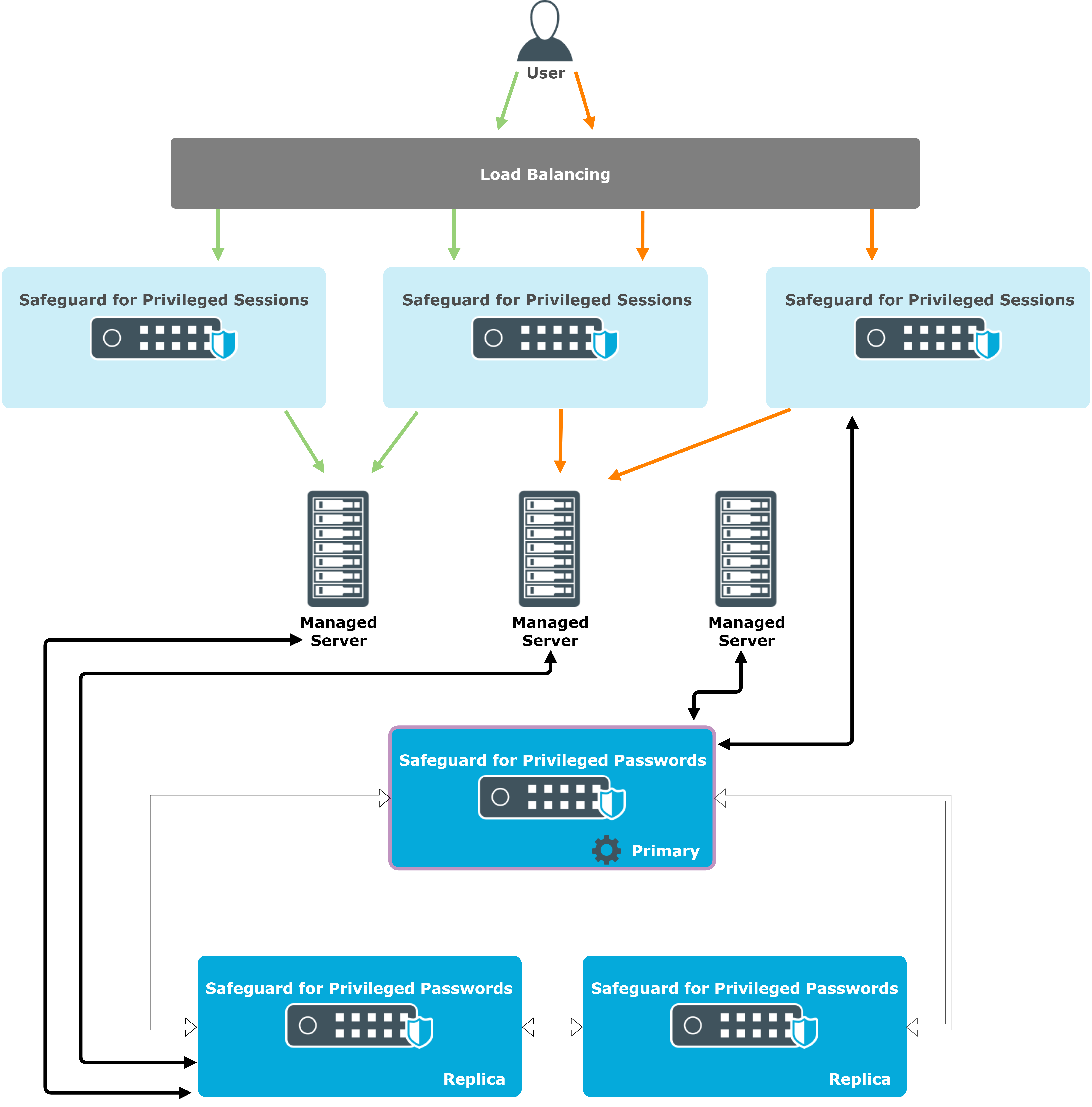
Scalability in joint SPP and SPS deployments
In case of SPP-initiated workflows, you can assign SPS scalability clusters to Managed Networks. The SPP cluster periodically checks the load on the members of the SPS cluster and assigns new connections to the best available appliance.
Figure 8: SPP-initiated workflow
In case of SPS-initiated workflows, SPS appliances always target the primary appliance of the SPP cluster, but the queries do not usually require scaling out to multiple SPP appliances.
Figure 9: SPS-initiated workflow
Disaster Scenarios
The sections in this chapter describe how Disaster Scenarios work in the Safeguard product line.
Disaster Scenarios in One Identity Safeguard for Privileged Passwords (SPP)
Failure of a replica node
If a replica node fails, the cluster detects that the node is out of the circulation and automatically redirects traffic. The cluster replicates all vital data between the nodes to prevent data loss.
One Identity recommends that managed networks contain multiple appliances so other nodes can take over the tasks of the failed node. You can reconfigure or disable managed networks to provide continuity of service.
Failure of the primary node
If the primary node fails, normal operation continues, but you cannot make changes to the configuration. You can promote any of the replica nodes manually to be the new primary node.
Failure of more than half of the cluster
If more than half of the cluster fails, the cluster switches into a read-only mode where you cannot make changes to the configuration and the cluster pauses password check and password change tasks. You can use Offline Workflow to manually or automatically restore the access request workflow. If the majority of the appliances have failed, you can use Reset Cluster to change to a new primary node without consensus. If all of the appliances in the cluster have failed, restore a backup.
Losing connectivity between appliances
The part of the cluster that becomes isolated and detects less than half of the original cluster switches into read-only mode, while the rest of the cluster remains active. In Offline Workflow you can configure the isolated nodes to continue serving access requests. When connection is re-established, the appliance state is automatically synchronized.
Disaster Scenarios in One Identity Safeguard for Privileged Sessions (SPS)
Failure of a node in a High Availability (HA) pair
If the failed node was the primary node, the hot-spare node automatically takes over the IP address and all traffic. Ongoing connections are disconnected. The cluster replicates all vital data between the pairs to prevent data loss. After replacing the failed node, perform a resynchronization.
NOTE: Resynchronization can last up to 24 hours.
In all of the following failure scenarios, if the failed node has a HA pair, the pair takes over all functionality automatically and the same recovery steps are required:
- Replace the failed node
- Resynchronize
Failure of a managed node (non-primary appliance) in the scalability cluster
If the managed node did not have a HA pair, traffic going through the managed node stops. The network configuration handles the outage and redirects traffic to another appliance in the cluster. In case of SPP-initiated workflows, SPP attempts to redirect the traffic towards a different SPS when the SPS configuration primary detects the outage. If central search is enabled, you can still perform searches, but video-like playback of sessions is not available.
Failure of the configuration primary in a scalability cluster
If the configuration primary did not have a HA pair, functioning nodes keep serving connections, but you cannot make any configuration changes in the cluster. You cannot move the configuration primary role to a different appliance, because the role must be restored from a backup.
Failure of the search master in a scalability cluster
If the search master did not have a HA pair, you cannot search in audit information, but all other functionality works. The other nodes buffer audit information until the search master node becomes available again. The nodes can survive approximately 24 hours of downtime when operating at full capacity, then they stop accepting new connections.
Losing connectivity between HA pairs
When connectivity is lost between the nodes of a HA pair, both appliances check whether they can detect the outside network. If a node only loses connection to the other node of the HA pair, both nodes start to operate as primary nodes. Two primary nodes cause service outage that you have to recover manually. To prevent this, One Identity recommends you to configure redundant HA links between the nodes.
For more information, see "Redundant heartbeat interfaces" in the Administration Guide.
Losing connectivity between nodes in a scalability cluster
If connection is lost between nodes in a scalability cluster, individual nodes continue serving new connections, but some of the functionality is lost until an outage recovery, such as making configuration changes or searching in new audit information.