
Check Point Log Exporter parser
The Check Point Log Exporter parser can parse Check Point log messages. These messages do not completely comply with the syslog RFCs, making them difficult to parse. The checkpoint-parser() of syslog-ng OSE solves this problem, and can separate these log messages to name-value pairs. For details on using value-pairs in syslog-ng OSE see Structuring macros, metadata, and other value-pairs. The parser can parse messages in the following formats:
<PRI><VERSION> <YYYY-MM-DD> <HH-MM-SS> <PROGRAM> <PID> <MSGID> - [key1:value1; key2:value2; ... ]
For example:
<134>1 2018-03-21 17:25:25 MDS-72 CheckPoint 13752 - [action:"Update"; flags:"150784"; ifdir:"inbound"; logid:"160571424"; loguid:"{0x5ab27965,0x0,0x5b20a8c0,0x7d5707b6}";]
Splunk format:
time=1557767758|hostname=r80test|product=Firewall|layer_name=Network|layer_uuid=c0264a80-1832-4fce-8a90-d0849dc4ba33|match_id=1|parent_rule=0|rule_action=Accept|rule_uid=4420bdc0-19f3-4a3e-8954-03b742cd3aee|action=Accept|ifdir=inbound|ifname=eth0|logid=0|loguid={0x5cd9a64e,0x0,0x5060a8c0,0xc0000001}|origin=192.168.96.80|originsicname=cn\=cp_mgmt,o\=r80test..ymydp2|sequencenum=1|time=1557767758|version=5|dst=192.168.96.80|inzone=Internal|outzone=Local|proto=6|s_port=63945|service=443|service_id=https|src=192.168.96.27|
If you find a message that the checkpoint-parser() cannot properly parse, open a GitHub issue so we can improve the parser.
By default, the Check Point-specific fields are extracted into name-value pairs prefixed with .checkpoint. For example, the action in the previous message becomes ${.checkpoint.action}. You can change the prefix using the prefix option of the parser.
Declaration:
@version: 3.22
@include "scl.conf"
log {
source { network(flags(no-parse)); };
parser { checkpoint-parser(); };
destination { ... };
};Note that the parser expects that the entire incorrectly formatted syslog message (starting with its <PRI> value) is in $MSG, which you can achieve by using flags(no-parse) on the input driver.
The checkpoint-parser() is actually a reusable configuration snippet configured to parse Check Point messages. For details on using or writing such configuration snippets, see Reusing configuration blocks. You can find the source of this configuration snippet on GitHub.
prefix()
| Synopsis: | prefix() |
Description: Insert a prefix before the name part of the parsed name-value pairs to help further processing. For example:
-
To insert the my-parsed-data. prefix, use the prefix(my-parsed-data.) option.
-
To refer to a particular data that has a prefix, use the prefix in the name of the macro, for example, ${my-parsed-data.name}.
-
If you forward the parsed messages using the IETF-syslog protocol, you can insert all the parsed data into the SDATA part of the message using the prefix(.SDATA.my-parsed-data.) option.
Names starting with a dot (for example, .example) are reserved for use by syslog-ng OSE. If you use such a macro name as the name of a parsed value, it will attempt to replace the original value of the macro (note that only soft macros can be overwritten, see Hard vs. soft macros for details). To avoid such problems, use a prefix when naming the parsed values, for example, prefix(my-parsed-data.)
By default, checkpoint-parser() uses the checkpoint. prefix. To modify it, use the following format:
parser {
checkpoint-parser(prefix("myprefix."));
};db-parser: Process message content with a pattern database (patterndb)
The structure of the pattern database
Using parser results in filters and templates
Downloading sample pattern databases
Correlating log messages using pattern databases
Triggering actions for identified messages
Actions and message correlation
Classifying log messages
The syslog-ng application can compare the contents of the received log messages to predefined message patterns. By comparing the messages to the known patterns, syslog-ng is able to identify the exact type of the messages, and sort them into message classes. The message classes can be used to classify the type of the event described in the log message. The message classes can be customized, and for example can label the messages as user login, application crash, file transfer, and so on events.
To find the pattern that matches a particular message, syslog-ng uses a method called longest prefix match radix tree. This means that syslog-ng creates a tree structure of the available patterns, where the different characters available in the patterns for a given position are the branches of the tree.
To classify a message, syslog-ng selects the first character of the message (the text of message, not the header), and selects the patterns starting with this character, other patterns are ignored for the rest of the process. After that, the second character of the message is compared to the second character of the selected patterns. Again, matching patterns are selected, and the others discarded. This process is repeated until a single pattern completely matches the message, or no match is found. In the latter case, the message is classified as unknown, otherwise the class of the matching pattern is assigned to the message.
To make the message classification more flexible and robust, the patterns can contain pattern parsers: elements that match on a set of characters. For example, the NUMBER parser matches on any integer or hexadecimal number (for example 1, 123, 894054, 0xFFFF, and so on). Other pattern parsers match on various strings and IP addresses. For the details of available pattern parsers, see Using pattern parsers.
The functionality of the pattern database is similar to that of the logcheck project, but it is much easier to write and maintain the patterns used by syslog-ng, than the regular expressions used by logcheck. Also, it is much easier to understand syslog-ng pattens than regular expressions.
Pattern matching based on regular expressions is computationally very intensive, especially when the number of patterns increases. The solution used by syslog-ng can be performed real-time, and is independent from the number of patterns, so it scales much better. The following patterns describe the same message: Accepted password for bazsi from 10.50.0.247 port 42156 ssh2
A regular expression matching this message from the logcheck project: Accepted (gssapi(-with-mic|-keyex)?|rsa|dsa|password|publickey|keyboard-interactive/pam) for [^[:space:]]+ from [^[:space:]]+ port [0-9]+( (ssh|ssh2))?
A syslog-ng database pattern for this message: Accepted @QSTRING:auth_method: @ for@QSTRING:username: @from @QSTRING:client_addr: @port @NUMBER:port:@ ssh2
For details on using pattern databases to classify log messages, see Using pattern databases.
The structure of the pattern database
The pattern database is organized as follows:
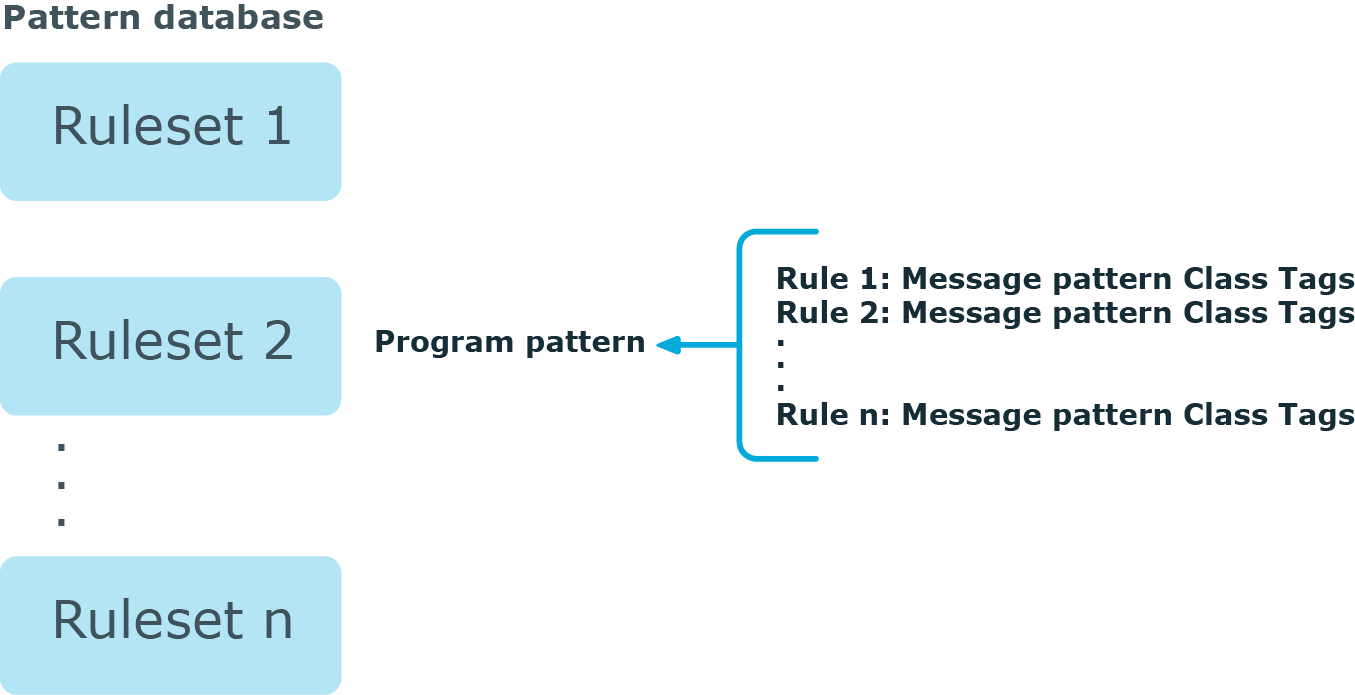
Figure 18: The structure of the pattern database
-
The pattern database consists of rulesets. A ruleset consists of a Program Pattern and a set of rules: the rules of a ruleset are applied to log messages if the name of the application that sent the message matches the Program Pattern of the ruleset. The name of the application (the content of the ${PROGRAM} macro) is compared to the Program Patterns of the available rulesets, and then the rules of the matching rulesets are applied to the message. (If the content of the ${PROGRAM} macro is not the proper name of the application, you can use the program-template() option to specify it.)
-
The Program Pattern can be a string that specifies the name of the application or the beginning of its name (for example, to match for sendmail, the program pattern can be sendmail, or just send), and the Program Pattern can contain pattern parsers. Note that pattern parsers are completely independent from the syslog-ng parsers used to segment messages. Additionally, every rule has a unique identifier: if a message matches a rule, the identifier of the rule is stored together with the message.
-
Rules consist of a message pattern and a class. The Message Pattern is similar to the Program Pattern, but is applied to the message part of the log message (the content of the ${MESSAGE} macro). If a message pattern matches the message, the class of the rule is assigned to the message (for example, Security, Violation, and so on).
-
Rules can also contain additional information about the matching messages, such as the description of the rule, an URL, name-value pairs, or free-form tags.
-
Patterns can consist of literals (keywords, or rather, keycharacters) and pattern parsers.
NOTE: If the ${PROGRAM} part of a message is empty, rules with an empty Program Pattern are used to classify the message.
If the same Program Pattern is used in multiple rulesets, the rules of these rulesets are merged, and every rule is used to classify the message. Note that message patterns must be unique within the merged rulesets, but the currently only one ruleset is checked for uniqueness.
If the content of the ${PROGRAM} macro is not the proper name of the application, you can use the program-template() option to specify it.
