When configuring your Splunk destination for syslog-ng Store Box (SSB), you have to configure the performance-related settings after you finish configuring the JSON message body settings for the Splunk destination.
Figure 191: Log > Destinations > <your-splunk-destination> - Configuring the Performance-related settings for your new Splunk destination
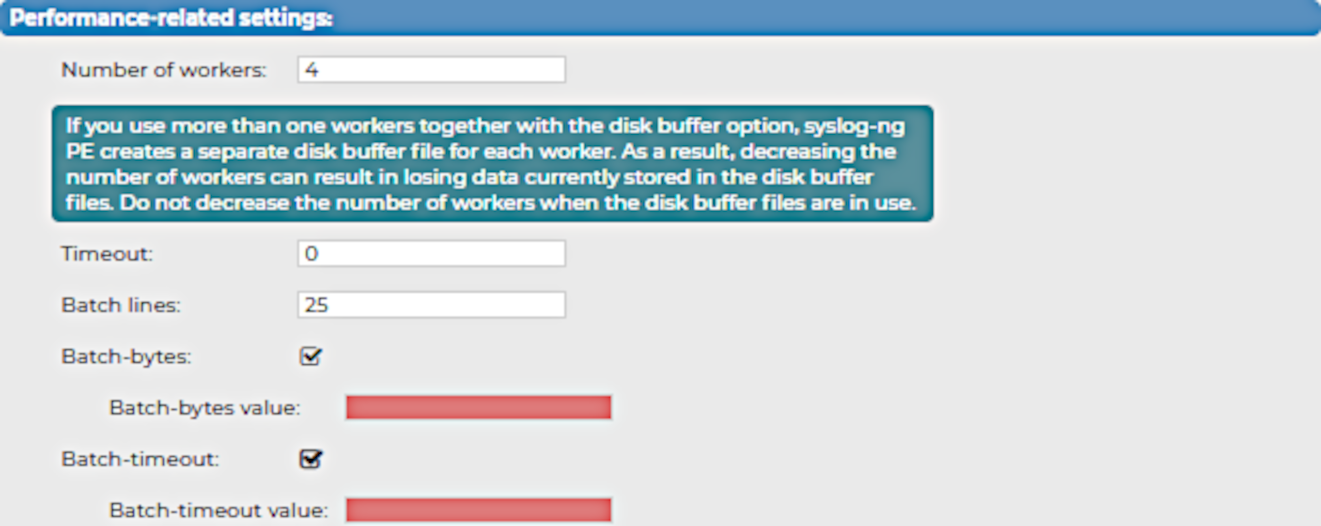
To configure the performance-related settings for your Splunk destination
-
Specify the Number of workers that you want SSB to use when sending messages to the server.
CAUTION: Hazard of data loss!
When you use more than one worker threads together with disk-buffering enabled, consider that the syslog-ng PE application behind SSB creates a separate disk-buffer file for each worker thread. This means that decreasing the number of workers can result in losing data currently stored in the disk-buffer files. To avoid data loss, One Identity recommends that you do not decrease the number of workers when the disk-buffer files are in use.
NOTE: Increasing the number of worker threads can drastically improve the performance of the destination.
-
Specify the Timeout (in seconds) that you want SSB to wait for an operation to complete, and attempt to reconnect the server if the configured timeout limit is exceeded.
-
In the Batch lines field, specify how many lines you want SSB to flush to a destination in one batch.
NOTE: SSB waits for the configured number of lines to accumulate, and when this number is reached, SSB sends the message lines to the destination in a single batch. For example, if you set Batch lines to 100, SSB waits for 100 message lines before sending them in one batch.
Consider the following when configuring the number of batch lines:
-
Increasing the number of batch lines increases throughput (because more messages are sent in a single batch), but also increases message latency.
-
If Batch-timeout option is disabled, the syslog-ng PE application behind SSB flushes the messages if it has sent the number of messages specified in Batch lines, or the queue became empty. If you stop or reload the syslog-ng PE application behind SSB, or if in case of network sources, the connection with the client is closed, the syslog-ng PE application behind SSB automatically sends the unsent messages to the destination.
-
If the Batch-timeout option is enabled and the queue becomes empty, SSB flushes the messages only if Batch timeout expires, or the batch reaches the limit set in Batch lines.
NOTE: Depending on your source configuration settings, your batch may not reach the Batch lines limit before your queue becomes empty, and SSB forwards your messages.
-
-
(Optional) Select Batch-bytes, and in the Batch-bytes value field, set the maximum size of payload in a batch (in bytes).
NOTE: When configuring Batch-bytes, consider the following:
-
If the size of the messages reaches this value, the syslog-ng PE application behind SSB sends the batch to your Splunk deployment even if the number of messages is less than the value you configure in the Batch-bytes field.
-
Consider that if Batch-timeout is enabled and the queue becomes empty, SSB flushes the messages only if Batch-timeout value expires, or if the message batch reaches the limit set in the Batch-bytes field.
-
-
(Optional) Select Batch-timeout, and in the Batch-timeout value field, specify the time SSB waits for Batch lines to accumulate in the output buffer.
SSB sends batches to the destinations evenly. The timer starts when the first message arrives to the buffer, so if only few messages arrive, SSB sends messages to the destination once every Batch timeout milliseconds at most.

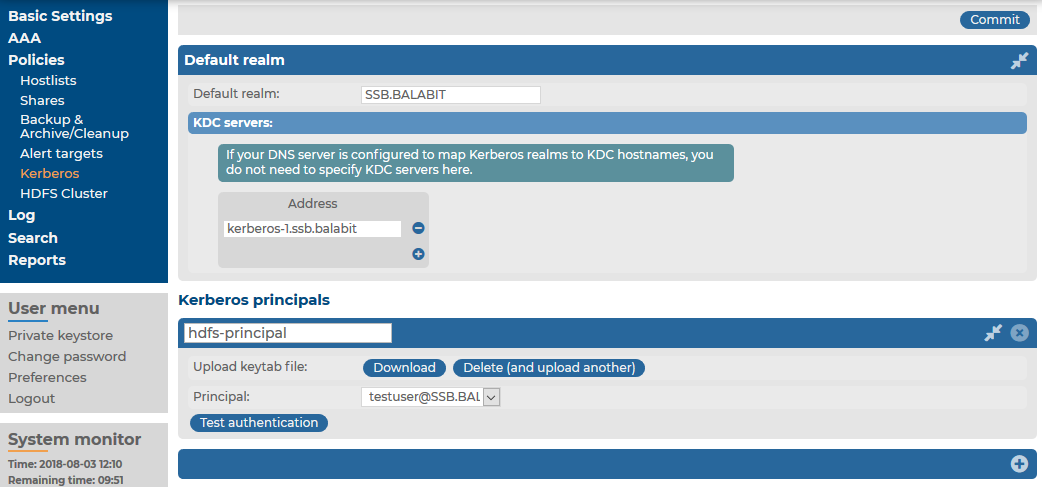
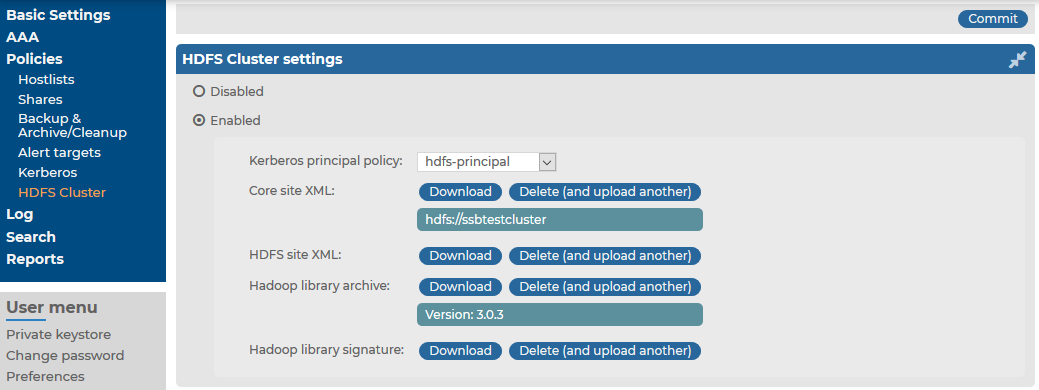
 to create a new policy.
to create a new policy. under Kerberos principals.
under Kerberos principals. .
.