In order to track inherited calculations as a result of changes to the system, the GenProcID is always passed to the DBQueue Processor operation. There may only be one entry in the DBQueue for each operation and object in case of follow-on operations. To map such processes, a new GenProcID is issued and used in subsequent processes. The conflicting processes and their GenProcID’s are saved in the DialogProcessSubstitute table.
When a new GenProcID is created for conflicting processes, the following rules apply:
-
Several of the same DBQueue Processor operations on one object are merged into one process (one GenProcID). This uses existing substitute processes if the number is identical to the predecessor (with respect to the root processes).
-
If further conflicts occur in the sequence, the GenProcIDs that have already been replaced are reset to the original and a new substitute is created.
-
A substitute is only valid for one set of original processes.
The QBM | DBQueue | GenProcIDReplaceLimit configuration parameter defines the limit for process substitutions. The maximum number of conflicting processes are mapped in the DialogProcessSubstitute table. If necessary, you can set the configuration parameter in the Designer and change the value.
Related topics
A hierarchical role structure exists which consists of 4 roles O1, O2, O3,and O4. Employee X is assigned to roles O1, O4, and O3. The assignment of software to roles is depicted in the following.
Figure 30: Role structure as in the example above
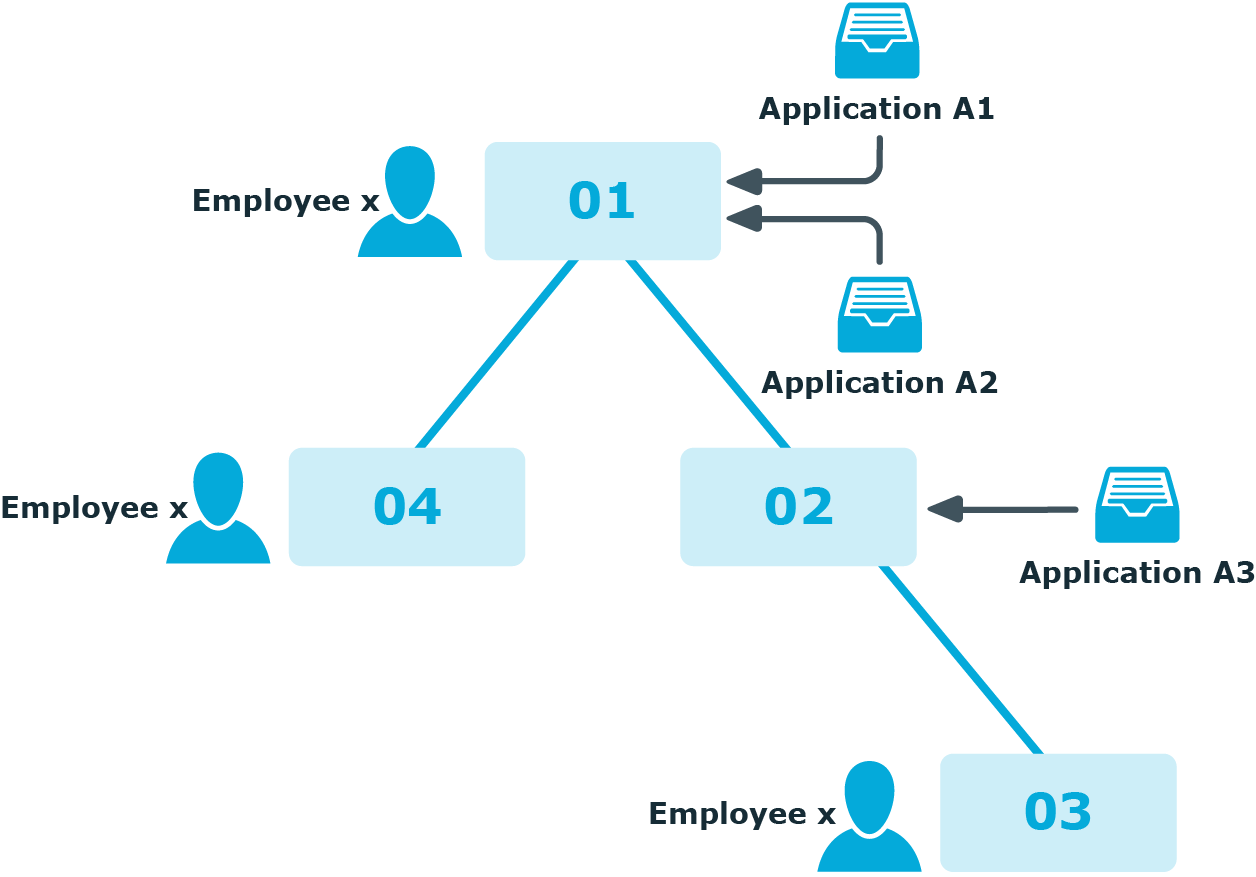
Three processes run between two DBQueue Processor runs, each with its own GenProcID:
-
P1: Software application A1 is assigned to the role O1
-
P2: Software application A2 is assigned to the role O1
-
P3: Software application A3 is assigned to the role O2
The following operations are in the DBQueue (DialogDBQueue table) and in the process information:
|
OrgHasApp |
O1 |
P1 |
|
OrgHasApp |
O1 |
P2 |
|
OrgHasApp |
O2 |
P3 |
The operation OrgHasApp cannot be subdivided with respect to O1 because the union of software applications is being calculated for O1. At this point, no more information is available as to which GenProcID has been entered by the assignment for which software application.
In order to achieve uniqueness for the combination of operation and object, a new GenProcID P4 is introduced and the two O1 operations are compacted into this GenProcID. P1 and P2 are noted in the DialogProcessSubstitute table as possible predecessors of P4 (but not clearly in the individual actions).
|
OrgHasApp |
O1 |
P4 |
|
OrgHasApp |
O2 |
P3 |
The following constellations can occur depending on whether the operation OrgHasApp is processed as a single step or in bulk:
- Case 1) O1 is calculated and then O2.
- Case 2) O2 is calculated and then O1.
- Case 3) O1 and O2 are calculated together simultaneously in a bulk operation.
After these operations have been run and assuming that they all cause changes to the total sets affected, the following situation arises:
Case 1) O1 is calculated and then O2.
|
OrgHasApp |
O2 |
P3 |
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O2 |
P4 |
|
OrgHasApp |
O3 |
P4 |
|
PersonHasApp |
X |
P4 |
Before the next DBQueue Processor run, the GenProcID’s must be compressed again, because the OrgHasApp operation did not produce a unique result for the object O2. P5 is introduced with possible predecessors P4 and P3.
|
OrgHasApp |
O2 |
P5 |
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O3 |
P4 |
|
PersonHasApp |
X |
P4 |
Now the calculation is done for O2:
|
OrgHasApp |
O3 |
P5 |
|
PersonHasApp |
X |
P5 |
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O3 |
P4 |
|
PersonHasApp |
X |
P4 |
Because O3 is not unique, P6 is introduced with possible predecessors P4 and P5.
|
OrgHasApp |
O3 |
P6 |
|
PersonHasApp |
X |
P5 |
|
OrgHasApp |
O4 |
P4 |
|
PersonHasApp |
X |
P4 |
After O3 and O4 have been calculated, the following situation exists:
|
PersonHasApp |
X |
P6 |
|
PersonHasApp |
X |
P5 |
|
PersonHasApp |
X |
P4 |
There is no uniqueness for object X such that P7 is introduced with possible predecessors P4, P5 and P6.
Case 2) O2 is calculated and then O1.
|
OrgHasApp |
O1 |
P4 |
|
OrgHasApp |
O2 |
P3 |
After running, the following entries are in the DBQueue:
|
OrgHasApp |
O1 |
P4 |
|
OrgHasApp |
O3 |
P3 |
The following situation is the result after the next step:
|
OrgHasApp |
O3 |
P3 |
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O2 |
P4 |
|
OrgHasApp |
O3 |
P4 |
|
PersonHasApp |
X |
P4 |
To achieve uniqueness for O3 a process P5 with possible predecessors P3 and P4 is created:
|
OrgHasApp |
O3 |
P5 |
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O2 |
P4 |
|
PersonHasApp |
X |
P4 |
After the calculations, the following situation exists:
|
PersonHasApp |
X |
P5 |
|
PersonHasApp |
X |
P4 |
There is no uniqueness for object X such that P6 is introduced with possible predecessors P4 and P5.
Case 3) O1 and O2 are calculated together simultaneously in a bulk operation.
|
OrgHasApp |
O1 |
P4 |
|
OrgHasApp |
O2 |
P3 |
After the first step in the calculation the following entries are in the DBQueue:
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O2 |
P4 |
|
OrgHasApp |
O3 |
P4 |
|
OrgHasApp |
O3 |
P3 |
|
PersonHasApp |
X |
P4 |
Uniqueness is achieved for O3 by introducing P5 with possible predecessors P3 and P4:
|
OrgHasApp |
O4 |
P4 |
|
OrgHasApp |
O2 |
P4 |
|
OrgHasApp |
O3 |
P5 |
|
PersonHasApp |
X |
P4 |
After the next step in the calculation, the following content is found
|
OrgHasApp |
O3 |
P4 |
|
PersonHasApp |
X |
P4 |
|
PersonHasApp |
X |
P5 |
After O3 has been calculated in the next run and has not created a new PersonHasApp entry, only X exists with P4 and P5 because X already exists with P4.
|
PersonHasApp |
X |
P4 |
|
PersonHasApp |
X |
P5 |
There is no uniqueness for object X such that P6 is introduced with possible predecessors P4 and P5.
All entries logged in One Identity Manager are initially saved in the One Identity Manager database. The proportion of historical data to total volume of a One Identity Manager database should not exceed 25%. Otherwise, performance problems may arise. You must ensure that log entries are regularly removed from the One Identity Manager database and archived.
The following methods are provided for regularly removing recorded data from the One Identity Manager database:
-
The data can be transferred directly from the One Identity Manager database into a One Identity Manager History Database. This is the default procedure for data archiving. Select this method if the servers on which the One Identity Manager database and the One Identity Manager History Database are located have network connectivity.
-
The data is deleted from the One Identity Manager database after a certain amount of time without being archived.
For detailed information about setting up archiving of data in a History Database, see One Identity Manager Data Archiving Administration Guide.
Detailed information about this topic
If records from separate sections are kept in the One Identity Manager database for a certain amount of time but are not archived later, you have the following options:
-
To exclude a certain section from archiving, do not configure it for export, just specify a retention period.
-
To delete all sections without archiving, specify a retention period. In the Designer, set the Common | ProcessState | ExportPolicy configuration parameter and enter the value NONE.
The records are deleted from the One Identity Manager database by DBQueue Processor when the retention period has ended. In addition, all entries for triggered actions are deleted if they have no corresponding records in those sections.
NOTE: If you do not specify a retention period, the records from that section are deleted from the One Identity Manager database during daily DBQueue Processor maintenance tasks.
Related topics
