
Using a configuration synchronization plugin
When synchronizing the central configuration across nodes, you may want to:
-
Keep certain parts in the configuration of individual nodes as-is.
-
Tailor certain parts of the central configuration to specific needs of individual nodes in the cluster (for example, your nodes may access external services at different network addresses).
You can achieve all of these by using a configuration synchronization plugin that contains transformations for the problematic parts. The plugin only runs on nodes that have the Managed Host role.
Customizing certain parts or features of a node using a configuration synchronization plugin has the same limitations as configuring SPS through the REST API. In other words, whatever you can configure through the REST API, you can configure the exact same settings using the plugin. One notable difference between the REST API and the plugin is that using the REST API, you can only read certain types of data (such as keys and passwords), while using the configuration synchronization plugin, you can write these types of data as well.
For details on how to configure SPS using the REST API, see REST API Reference Guide.
Data structures in the plugin are represented as nested JSON objects. For object references, the plugin uses keys.
The plugin works with the following key parameters:
- local_config: The current configuration of a Managed Host node (those parts that can be configured through the REST API).
- merged_config: The configuration of the Central Management node that is about to be synced to the Managed Host node (those parts that can be configured through the REST API), with settings related to networking, local services, management, and the license of SPS whitelisted. These settings are never overwritten by configuration synchronization.
- node_id: The unique ID of the Managed Host node in the cluster (you can retrieve this identifier by querying the /api/cluster/nodes endpoint through the REST API).
- plugin_config: The configuration of the plugin provided as free-form text. Specifying the configuration of the plugin is optional. It enables you to run configuration synchronization on each cluster with different parameters if you have multiple clusters.
Example: Customizing an IP address in a connection policy
For example, an RDP connection policy on a Managed Host node specifies the following client and target addresses:
$ curl ... https://<url-of-Central-Management-node>/api/configuration/rdp/connections/<id-of-the-connection-policy>
{
"body": {
"network": {
"clients": [
"0.0.0.0/0"
],
"ports": [
3389
],
"targets": [
"10.30.255.28/24"
]
},
},
...
}
Let's suppose that on the Central Management node, an RDP connection policy is configured with these details:
$ curl ... https://<url-of-Managed-Node>/api/configuration/rdp/connections/<id-of-the-connection-policy>
{
"body": {
"network": {
"clients": [
"0.0.0.0/0"
],
"ports": [
3389
],
"targets": [
"10.30.255.8/24"
]
},
},
...
}
To ensure that the details of the connection policy on the Managed Host node are kept as-is after configuration synchronization, add the following lines to the plugin main.py file:
$ cat main.py
def merge(local_config: dict, merged_config: dict, node_id: str, plugin_config: str, **kwargs):
merged_config['rdp']['connections'][<id-of-the-connection-policy>]['network']['targets'][0] = "10.30.255.8/24"
return merged_config
Due to possible new (as yet undefined) parameters, it is good practice to close the parameter list of the merge function with **kwargs.
In case you need assistance with writing customized transformations, contact our Professional Services Team, and a One Identity Service Delivery Engineer will be able to help you.
|
|
NOTE:
Configuration settings related to networking (Basic Settings > Network), local services (Basic Settings > Local Services), and the license of SPS (Basic Settings > System > License) are not overwritten on the nodes by configuration synchronization even when not using a plugin. For the management of SPS (Basic Settings > Management), the following configuration settings are not overwritten:
|

To use a configuration synchronization plugin
-
Upload a configuration synchronization plugin:
-
Navigate to Basic Settings > Plugins.
-
Browse for the file, and click Upload.
NOTE: It is not possible to upload or delete plugins if SPS is in sealed mode.
-
-
Enable the plugin:
-
Navigate to Basic Settings > Cluster management > Configuration synchronization plugin.
-
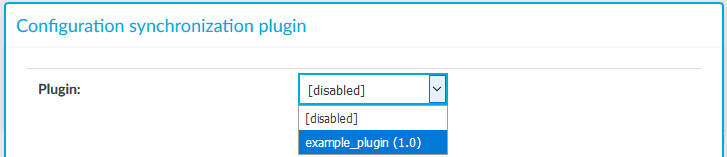
Select the plugin you have uploaded.
Figure 95: Basic Settings > Cluster management — Select configuration synchronization plugin
-
- Optional: Enter the configuration of the plugin in the Configuration free-form text field. Specifying the configuration of the plugin enables you to run configuration synchronization on each cluster with different parameters if you have multiple clusters.
-
Click
.
You can also upload and enable the configuration synchronization plugin through REST. For details, see "Upload and enable a configuration synchronization plugin" in the REST API Reference Guide.
Monitoring the status of nodes in your cluster
The following describes how to monitor the status of nodes in your cluster.
To monitor the status of nodes in your cluster
-
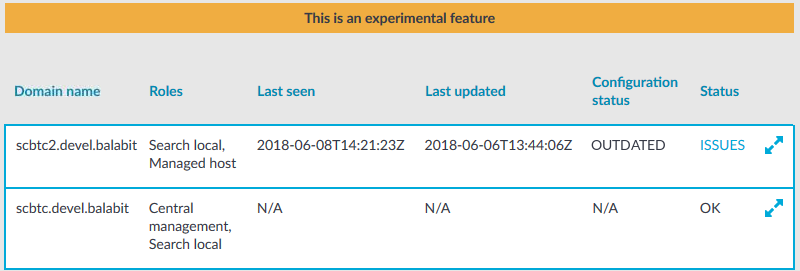
On the web interface of your Central Management node, navigate to Basic Settings > Cluster management. This page displays all nodes of a cluster.
Figure 96: Basic Settings > Cluster management — Monitor status of nodes
The following status information is displayed for each node:
-
Last seen: The last time the node sent status information to the Central Management node, in ISO 8601 format.
-
Last updated: The last time the node's configuration was synchronized, in ISO 8601 format.
- Configuration status: Indicates the status of configuration synchronization. It has the following values:
- UP-TO-DATE: The node has fetched the latest configuration from the Central Management node, and has applied it. It is in sync with the Central Management node.
- PENDING: There has been a configuration change on the Central Management node, and the change has not been synchronized yet to the node.
- OUTDATED: There has been some error on the node and therefore it is running an old configuration.
- N/A: This can mean the following:
- The node has not fetched any configuration yet.
- The node is the Central Management node, so it is not fetching its configuration from any other node.
-
Status: Indicates whether any issues occurred during configuration synchronization. It has the following values:
-
OK: Configuration synchronization was successful, no issues occurred.
-
ISSUES: While synchronizing configuration, some issue(s) occurred. Click ISSUES to find out the details.
-
OFFLINE: Indicates that status information was sent by the node longer than 60 seconds ago.
-
You can monitor the status of your nodes through the REST API, too. For details, see REST API Reference Guide and REST API Reference Guide.
-
Updating the IP address of a node in a cluster
When you have joined a node to a cluster, you can still change the IP address of the node if it is a Managed Host node.
To update the IP address of a Managed Host node that is already the member of a cluster
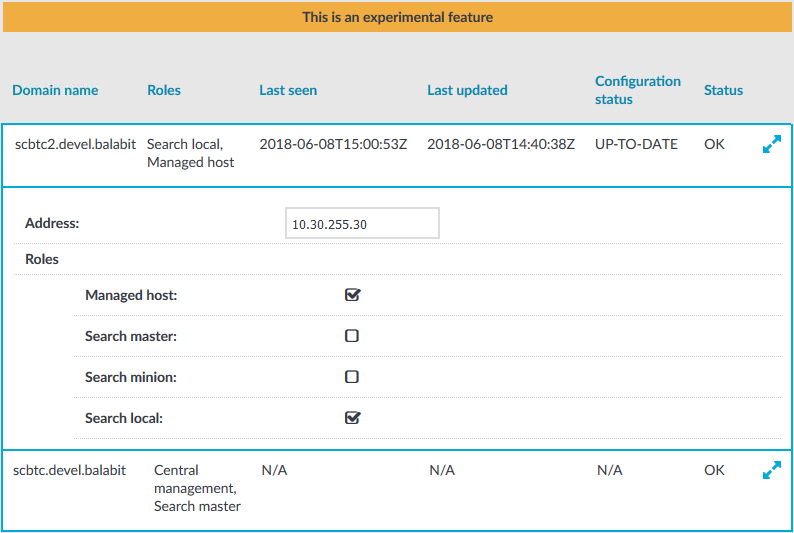
- On the web interface of your Central Management node, navigate to Basic Settings > Cluster management.
- Click
next to the Managed Host node that you want to update.
- In the Address field, update the IP address of the node.
Caution: Ensure that you are making the change for the Managed Host node. Do not change the IP address of the Central Management node.
Figure 97: Basic Settings > Cluster management — Update IP address of node
- Click
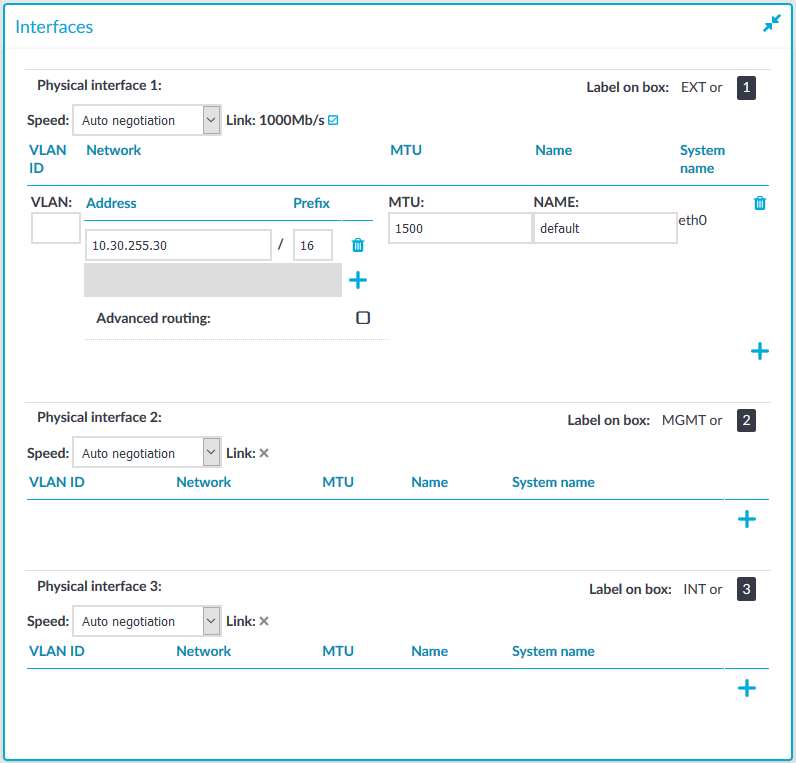
- On the web interface of the node whose IP address you want to update, navigate to Basic Settings > Network > Interfaces.
- In the Address field, update the IP address of the node.
Figure 98: Basic Settings > Network > Interfaces — Update IP address of node
- Click

Managing a high availability One Identity Safeguard for Privileged Sessions (SPS) cluster
High availability (HA) clusters can stretch across long distances, such as nodes across buildings, cities or even continents. The goal of HA clusters is to support enterprise business continuity by providing location-independent failover and recovery.
To set up a high availability cluster, connect two One Identity Safeguard for Privileged Sessions (SPS) units with identical configurations in high availability mode. This creates a primary-secondary (that is, active-backup) node pair. Should the primary node stop functioning, the secondary node takes over the IP addresses of the primary node's interfaces. Gratuitous ARP requests are sent to inform hosts on the local network that the MAC addresses behind these IP addresses have changed.
The primary node shares all data with the secondary node using the HA network interface (labeled as 4 or HA on the SPS appliance). The disks of the primary and the secondary node must be synchronized for the HA support to operate correctly. Interrupting the connection between running nodes (unplugging the Ethernet cables, rebooting a switch or a router between the nodes, or disabling the HA interface) disables data synchronization and forces the secondary node to become active. This might result in data loss. You can find instructions to resolve such problems and recover a SPS cluster in Troubleshooting a One Identity Safeguard for Privileged Sessions (SPS) cluster.
|
|
NOTE:
HA functionality was designed for physical SPS units. If SPS is used in a virtual environment, use the fallback functionalities provided by the virtualization service instead. |
The Basic Settings > High Availability page provides information about the status of the HA cluster and its nodes.
Figure 99: Basic Settings > High Availability — Managing a high availability cluster
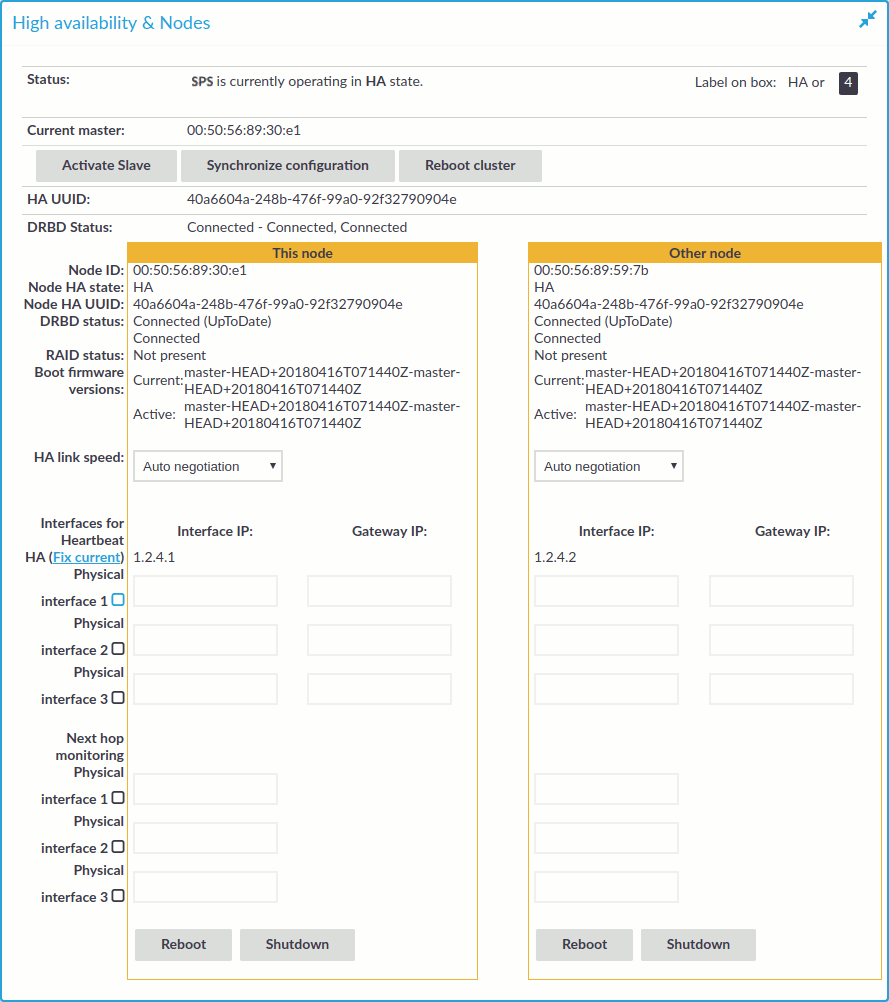
The following information is available about the cluster:
-
Status: Indicates whether the SPS nodes recognize each other properly and whether those are configured to operate in high availability mode. For details, see Understanding One Identity Safeguard for Privileged Sessions (SPS) cluster statuses.
-
Current master: The MAC address of the high availability interface (4 or HA) of the primary node. This address is also printed on a label on the top cover of the SPS unit.
-
HA UUID: A unique identifier of the HA cluster. Only available in High Availability mode.
-
DRBD status: Indicates whether the SPS nodes recognize each other properly and whether those are configured to operate in high availability mode. For details, see Understanding One Identity Safeguard for Privileged Sessions (SPS) cluster statuses.
-
DRBD sync rate limit: The maximum allowed synchronization speed between the primary and the secondary node. For details, see Adjusting the synchronization speed.
The active (that is, primary) SPS node is labeled as This node. This unit inspects the SSH traffic and provides the web interface. The SPS unit labeled as Other node is the secondary node that is activated if the primary node becomes unavailable.
The following information is available about each node:
-
Node ID: The MAC address of the HA interface of the node. This address is also printed on a label on the top cover of the SPS unit.
For SPS clusters, the IDs of both nodes are included in the internal log messages of SPS.
-
Node HA state: Indicates whether the SPS nodes recognize each other properly and whether those are configured to operate in high availability mode. For details, see Understanding One Identity Safeguard for Privileged Sessions (SPS) cluster statuses.
-
Node HA UUID: A unique identifier of the cluster. Only available in High Availability mode.
-
DRBD status: The status of data synchronization between the nodes. For details, see Understanding One Identity Safeguard for Privileged Sessions (SPS) cluster statuses.
-
RAID status: The status of the RAID device of the node. If it is not Optimal, there is a problem with the RAID device. For details, see Understanding One Identity Safeguard for Privileged Sessions (SPS) RAID status.
-
Boot firmware version: Version number of the boot firmware.
The boot firmware boots up SPS, provides high availability support, and starts the core firmware. The core firmware, in turn, handles everything else: provides the web interface, manages the connections, and so on.
-
HA link speed: The maximum allowed speed between the primary node and the secondary node. The HA link's speed must exceed the DRBD sync rate limit, else the web UI might become unresponsive and data loss can occur.
-
Interfaces for Heartbeat: Virtual interface used only to detect that the other node is still available. This interface is not used to synchronize data between the nodes (only heartbeat messages are transferred).
You can find more information about configuring redundant heartbeat interfaces in Redundant heartbeat interfaces.
-
Next hop monitoring: IP addresses (usually next hop routers) to continuously monitor both the primary node and the secondary node by using ICMP echo (ping) messages. If any of the monitored addresses becomes unreachable from the primary node while being reachable from the secondary node (in other words, more monitored addresses are accessible from the secondary node), then it is assumed that the primary node is unreachable and a forced takeover occurs – even if the primary node is otherwise functional. For details, see Next-hop router monitoring.